When I hear the word “quantum”, I think of all the misconceptions and crazy ideas people associate with it in a lot of popular media. Physicists are great (and terrible) at coming up with names, and the word “quantum” is such an example of a word with a lot of baggage attached. Pair it with the word “computer”, however, and the misconceptions skyrocket, sometimes turning into full-blown hype. The reality (at the time of this writing) is much more modest: quantum computing presents an opportunity for thinking of computation differently, and the subsequent years will see how this plays out when theory meets experiment and engineering.
There’s a ton to talk about when it comes to quantum computing, but in this essay, I want to share with you something called a quantum error correcting code. It does what it says on the tin, and corrects errors that can accumulate during a computation. There are many such proposals, but one of the most popular is called the surface code, whose name will make sense as we dive into the details. The surface code is a proposal for how we can build a quantum computer that is robust to errors, but is only one step in the process. This essay is devoted to the surface code, how it works, and the challenges it faces when it comes to implementation.
Quantum information in a nutshell
To really get why we even care about quantum computers, you need to know about quantum information. I would write an essay about it, but thankfully, the awesome Michael Nielsen has done this (and a few more) on his website Quantum Country. There, he goes into a great amount of detail and writes beautifully, so I would recommend you start with his first essay there if you need more details.
For our purposes, we will only need the basics. In quantum theory, a qubit (a portmanteau of “quantum bit”) is just a system that can have two levels. If you’re trying to implement a qubit in a laboratory, you might want to use an atom which has a ground state and an excited state. This gives you the two levels required for a qubit.
The way physicists write this is as such:
|ψ〉 = a|0〉 + b|1〉, |a|2 + |b|2 = 1.
The symbol |⋅ 〉 is used to denote vectors1, with |0〉 and |1〉 being the basis vectors. The coefficients a and b are complex numbers whose sum of squares adds to one. That’s a qubit, for our purposes.
Notice how similar this is to the bit, the classical counterpart to the qubit. A bit, as you might know, is just a 0 or a 1. There are two states, and that’s it. The same is true for our qubit, except we can also have combinations of the basis vectors. This is different from the bit, and it’s part of the reason as to why people are excited for the possibilities of quantum computing.
Another structure that’s important is the tensor product. This is what lets us combine multiple qubits together into a system. If we have two qubits, the way to combine them is: |ψ〉 ⊗ |φ〉.
The details of the tensor product aren’t necessary for us here, except for the fact that it lets us treat the combined system as a sort of “concatenation” of the individual components. When we will later have operators acting on our qubits, we can basically act the operator on specific qubits, while doing nothing to the others.
So in a nutshell, that’s what quantum information is. We get states that are combinations (in the physics lingo, we say “superpositions”) of the basis states, which means we have more possibilities than with bits. This is what enables protocols like quantum teleportation and quantum search (seriously, Michael Nielsen is awesome, and it’s worth checking out his work).
With these tools in hand, let’s get to the difficulties of quantum computing, which will lead us to the surface code.
Challenges of quantum computing
As we’ve seen, quantum information is different enough from classical information that we cannot use all of the tricks we’ve developed for classical computers when trying to make a quantum computer work.
No matter what system you use though (classical or quantum), your device will have errors that occur. If anything, we can appeal to the law of experiments: anything a theorist thinks up will always be imperfect in the laboratory. Despite what theoretical physicists are taught in school, you can’t simply wish away every source of noise or error in a system. In the real world, we need to take them into account. Moreover, if we didn’t design our computers with noise in mind, they would be incredibly fragile to perturbations. Not something you want when manipulating sensitive information like in your bank account.
In classical computing, correcting errors is straightforward. Let’s use the simplest example in the book: the three-bit repetition code.
Imagine your friend asks you over the internet if you want to play squash or go running later, with the instructions of replying 0 for squash and 1 for running. As a runner, you don’t want to be stuck within four walls for the next hour, so you send the message 1. Unfortunately, your device is getting old and prone to messing up, so it sends your friend a 0 instead. Your friend then shows up to your place with their racquet while you are lacing up your running shoes. Not a great situation.
What went wrong? Well, if your friend receives a 0 or a 1, how are they supposed to know this is what you sent? They need to be reasonably confident that there’s no way for the information to get corrupted as it passes from you to them. But if there’s some probability p that the bit gets flipped, it’s difficult to say what the real message was (unless p is super small).
It would be much better if there was some sort of redundancy built into the message that could increase your friend’s confidence that the received message is what you sent. At the very least, it would be nice if they could tell if something went wrong, and knew how to fix it. This is precisely the idea of error correction.
Here’s a strategy that works better. Let’s assume p is small, but not super small. Instead, of replying with 0 or 1, you’re going to encode those two messages within larger messages. In particular, you will use 000 to represent the message “0”, and 111 to represent the message “1”.
Now, even though the probability of flipping a bit is p, it’s going to take a lot more to scramble the message! If we want the wrong message to be sent, each of the individual bits has to be flipped. Sending 000 requires each of them to flip to become 111 (the wrong message). Assuming that errors are independent (unlikely in real life, but it illustrates the point), this will occur with probability p×p×p = p3. If p is already small, this new value will be much smaller. For example, if p = 0.01, then p3 = 0.000001, which is very small. By repeating the message three times, you’re able to suppress the chance that the wrong message gets sent.
But what if you send 000 and your friend receives 001? Well, if the two of you agreed that the only messages you could send are 000 and 111, then there are two cases. If you sent 000, getting to 001 requires flipping the last bit, which happens with probability p. On the other hand, if you sent 111, getting 001 requires flipping the first and second bits, which occurs with probability p2. Again, if p is already super small, then p > p2, so your friend can be confident that you sent 000. It won’t work all the time, but it will work often enough (to the extent that you make sure your equipment has a low error rate!). This is called “majority rules”, since the intended message is the one that appears the most in the string of bits. In the error correction jargon, the code we just came up with is able to correct single bit errors (remember, if two bits get flipped, then we will mistakenly “correct” to the opposite message).
Look at what we have here. By increasing from one bit to three bits, we’ve come up with a way to ensure (probabilistically) that the message which gets sent is the one that is eventually received. The recipient might have to think a little bit when the message is garbled with 0s and 1s, but they can do it.
The snag is that this doesn’t quite work in the quantum case. In particular, there’s a key issue which plagues a lot of work in quantum theory: measuring systems often collapses their superpositions. Collapse the superposition, and you’re just dealing with essentially classical information all over again.
Where did we use measurement in the protocol I’ve described above? It’s in the way that the recipient looked at the message and made a judgment based on that. When they go from 001 back to 000, they need to physically look at the message. This act of looking is the equivalent of performing a measurement on a quantum system, and that’s bad news when it comes to error correction. After all, how are we supposed to know what to do to corrupted information if we can’t look at it?
There are other problems too. We can’t just implement the repetition code stated above, because of something called the “No-Cloning theorem”. This means we can’t just copy our messages three times and let the recipient use the majority rules selection. We’ll have to be more clever than this. To make matters worse, the kinds of errors you can have on a qubit are much more numerous than with a bit. That’s because a bit can be flipped from 0 to 1 or vice versa. With a qubit, we can do a bunch of things to the coefficients a and b of the quantum state, as long as we keep the qubit normalized. Since the two coefficients have the constraint that they lie on a circle, this means we have a continuum of possible errors. We crafted the repetition code above to detect a bit flip error, but how are we going to correct all of these possible errors?
These both make things look bad. And we haven’t even discussed the engineering challenges of making a qubit! The good news is that these challenges are surmountable (well, the engineering question is still open). I won’t go into all of the details for how we solve these problems, but I will touch on them briefly here.
For the issue of cloning states, the problem is that we can’t have a quantum operation that performs |ψ〉⊗|φ〉 → |ψ〉⊗|ψ〉. In particular, this means you can’t encode your message by just sending three copies of the same state (unless it’s a very particular state). I won’t do the No-Cloning theorem justice here, so I will refer you to this short and sweet proof. So a straightforward repetition code is out of the question. Thankfully, there are similar constructions that work, and are used to great effect.
The discretization of errors is one that will be relevant to us, so I’ll talk about this a bit more. The big idea is that quantum states evolve like this: |ψ〉’ = U|ψ〉, where U is a unitary matrix describing, in our case, an error that has occurred. In the single-qubit case (this also generalizes to multi-qubit states), the matrix is 2×2. What we can do is then perform a Taylor expansion of U around some small perturbation. Once you do that, you can use the fact that the set {I, X, Y, Z} (the Pauli matrices along with the identity) forms a basis for 2×2 matrices, which means we can describe the error as being the result of a linear combination of them (to first order). If the perturbation is small—which makes sense for error correction since we want to get back to our original state and having it pushed too far away will mean we likely mix it up with another state—we can only look at these first terms in the expansion. We’ll have something that looks like:
|ψ〉’=(I + ε(sum of Pauli errors) )|ψ〉.
To get back to our original state, all we have to do is apply the same Pauli operators again. Since they each square to the identity, we can recover the state and correct errors. Plus, since quantum mechanics is a linear theory, everything works out perfectly.
It’s worth pausing to appreciate what this means. We’ve essentially chopped up infinity into a finite number of slices. The matrix U could have described any error, and the fact that the Pauli matrices can describe all 2×2 matrices came to our rescue. This means we’ve turned a problem of continuous errors into a discrete set: {I,X,Y,Z}, a pretty cool feat.
Now that we’ve talked about some of the challenges inherent with quantum computing, we’re ready to dive into the lovely quantum error correction structure which is the surface code.
Parities and the surface code
One of the easiest algebraic systems to get a feel for is that of a switch. There are two modes: on and off, one or zero. It’s simple, it’s straightforward, and even though it might be unfamiliar to some at the beginning, it doesn’t take a whole lot of practice before this system becomes ingrained.
Computers are built on bits, and we all know how powerful computers can be. Even with such a simple algebraic system, bits can give us a lot of flexibility when it comes to computation. In terms of an addition and multiplication table, the binary system works as follows.
Addition:
| + | 0 | 1 |
|---|---|---|
| 0 | 0 | 1 |
| 1 | 1 | 0 |
Multiplication:
| × | 0 | 1 |
|---|---|---|
| 0 | 0 | 0 |
| 1 | 0 | 1 |
What’s nice about using bits is that they can encode anything that can take one of two states. In particular, bits can encode the parity of a whole number, which is just a fancy way of saying if it’s even (we use the bit 0) or odd (we use the bit 1).
What I want to show you in this essay is how this idea of parity can let us build codes that can be used for quantum computers. It’s all about asking the right kind of question, and the notion of parity will let us do so.
Stabilizers and measurement
There are many challenges for quantum computing. As I mentioned above, these include being unable to copy arbitrary quantum states and avoiding measurement because this collapses the quantum state (destroying the superpositions we want). We will build on these considerations in this essay.
With the surface code, the idea is simple: find a way to encode the information of a qubit while also allowing us to detect errors that occur.
Because of the discretization of errors, the possible errors on our lattice can be be anything comprised of I, X, Y, and Z. This includes multiple-qubit errors. For example, if we had three qubits, an error operator could look like X1Y2I3, where the structure linking them together is the tensor product. This simply means the first qubit would have an error X being applied to it, the second qubit would have Y, and the final qubit would have I. Sometimes the I operator is omitted in order to keep things compact, particularly when there are a lot of qubits.
Let’s start building up our surface code. The first ingredient is to arrange our qubits on a lattice, with each physical qubit on a lattice site. We will use N to count the number of physical qubits per lattice side, so there will be a total of N2 physical qubits. Also, due to some technicalities with boundary conditions, N has to be an odd integer greater than one (we’ll see why soon).
Doing this gives us a lattice that looks like so:
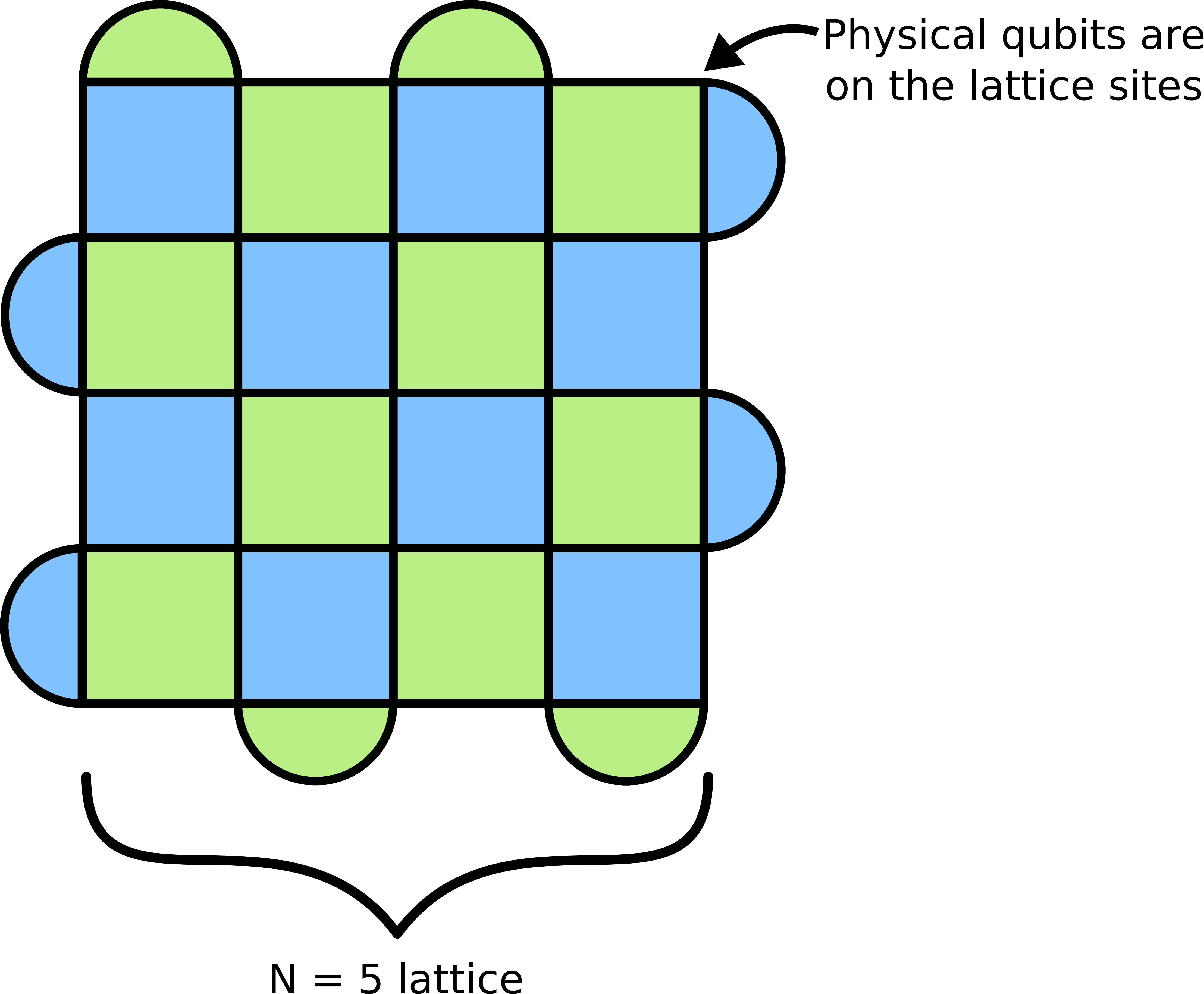
We now want to define our stabilizers (the checkerboard pattern). The stabilizers are a way to encode multiple states of the physical qubits into one logical state, giving us a more robust way to do a computation. The important part here is that the stabilizers are a set of operators which commute with each other and preserve the quantum state. (Note that, in the mathematical terminology, the group of operators is called the stabilizer, and the group elements are called stabilizer generators. This gets to be a mouthful though, so I’ll simply refer to the operators as stabilizers.) In particular, if |ψ〉 is our quantum state, than any stabilizer M we take has the property that M|ψ〉 = |ψ〉. This tells us that the stabilizers don’t do anything to the underlying quantum state. They “stabilize” it. In more technical terms, the state |ψ〉 is an eigenvector of the stabilizer M, with eigenvalue +1. The surface code is then defined as the quantum state of the lattice of N2 physical qubits where the stabilizers are all in their +1 eigenstate.
I don’t know about you, but I like this topic just for the beautiful diagrams! It isn’t only visually appealing; it also encodes the stabilizers themselves. The great thing is that you can understand it in both a visual and mathematical sense. It’s worth taking the time to do both.
Graphically, the stabilizers are defined as such:
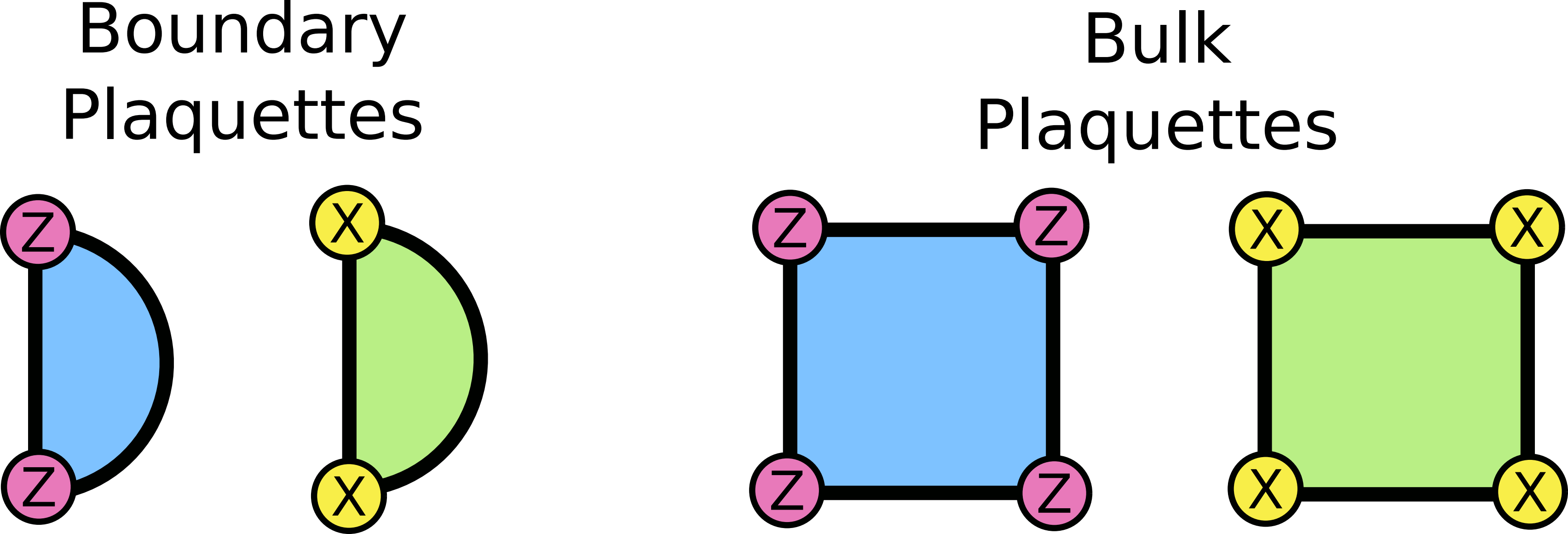
The squares and half-moon shapes are what we call plaquettes, and the colours represent either an X stabilizer (green) or a Z stabilizer (blue). They work by having an X or Z operator on each lattice site, in the tensor product structure I mentioned before. So a square X stabilizer would look like XXXX, where the operators act on the qubits touching that square. The same is true for the Z stabilizers. (Why aren’t there any stabilizers associated with the Y Pauli operator? See here2.)
What’s up with these weird half-moon plaquettes? It’s because of boundary conditions. The surface code has open boundary conditions, which means we have to modify things a bit. Having these operators along the edge ensures that everything works correctly.
It’s also not a coincidence that the stabilizers are either four Pauli operators or two. We’ll get to this soon.
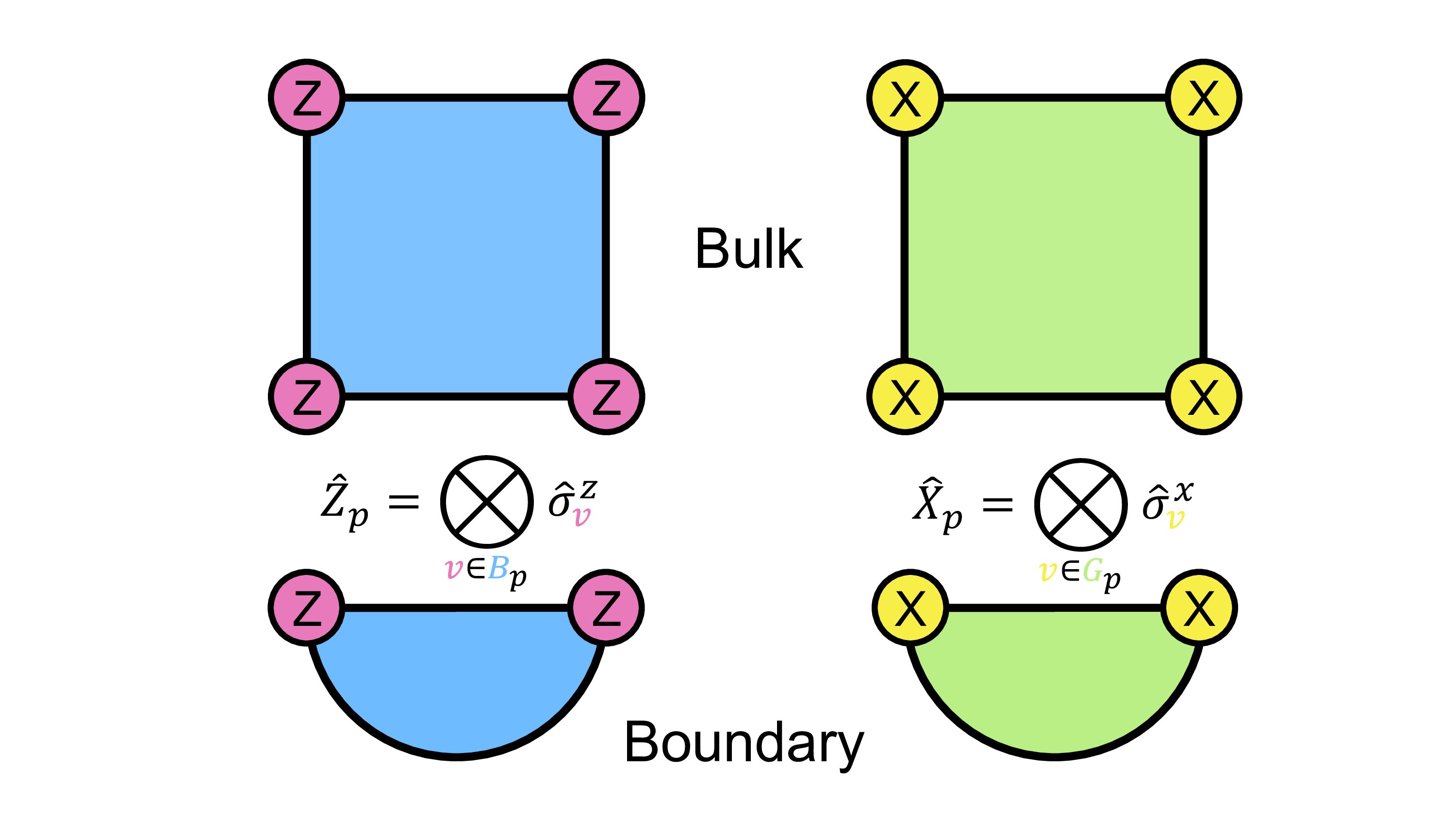
Mathematically, the stabilizers are defined as:
Xp = ⊗v∈Gpσxv and Zp = ⊗v∈Bpσzv.
The symbol p represents the plaquettes, v are the lattice sites, and σx and σz are the Pauli X and Z matrices (I’m using a slightly different notation here to clarify the difference between Xp, Zp and the Pauli matrices themselves).
Let’s break down the notation, which can be a little intimidating the first time you see it. The G and B simply stand for the green and blue plaquettes that make the lattice, and the subscript p is a way of enumerating them. It’s always good to have a way of listing things, and the indices do just that. Next, the symbol ⊗ is just the tensor product, which I mentioned above. This tells us that there are are going to be multiple operators “concatenated” together, which is exactly what I wrote above when I gave the example of a stabilizer being XXXX. The subscript on the tensor product symbol tells us which vertices we are considering when building our stabilizer. For any plaquette p, there will be either two or four vertices which touch it. The v∈ p notation tells us to take all of those vertices when building the stabilizer. Finally, we have the Pauli operators X and Z, with indices that tell us which qubit they act on. The following handy diagram summarizes all of this. (There are “hats” on the symbols because they are technically operators. I don’t have them in the text here because they are tricky to format.)
We should check that these stabilizers actually commute with themselves, as a good stabilizer code should do (because we want to measure their eigenvalues simultaneously to detect errors). We can go through a couple of cases and make sure that things work out. Before we do, it’s important to remember the rules of Pauli matrices: they anticommute with each other, which is a fancy way of saying that XZ = −ZX.
Suppose we’re looking at two stabilizers that are far away from each other, like in the following diagram:
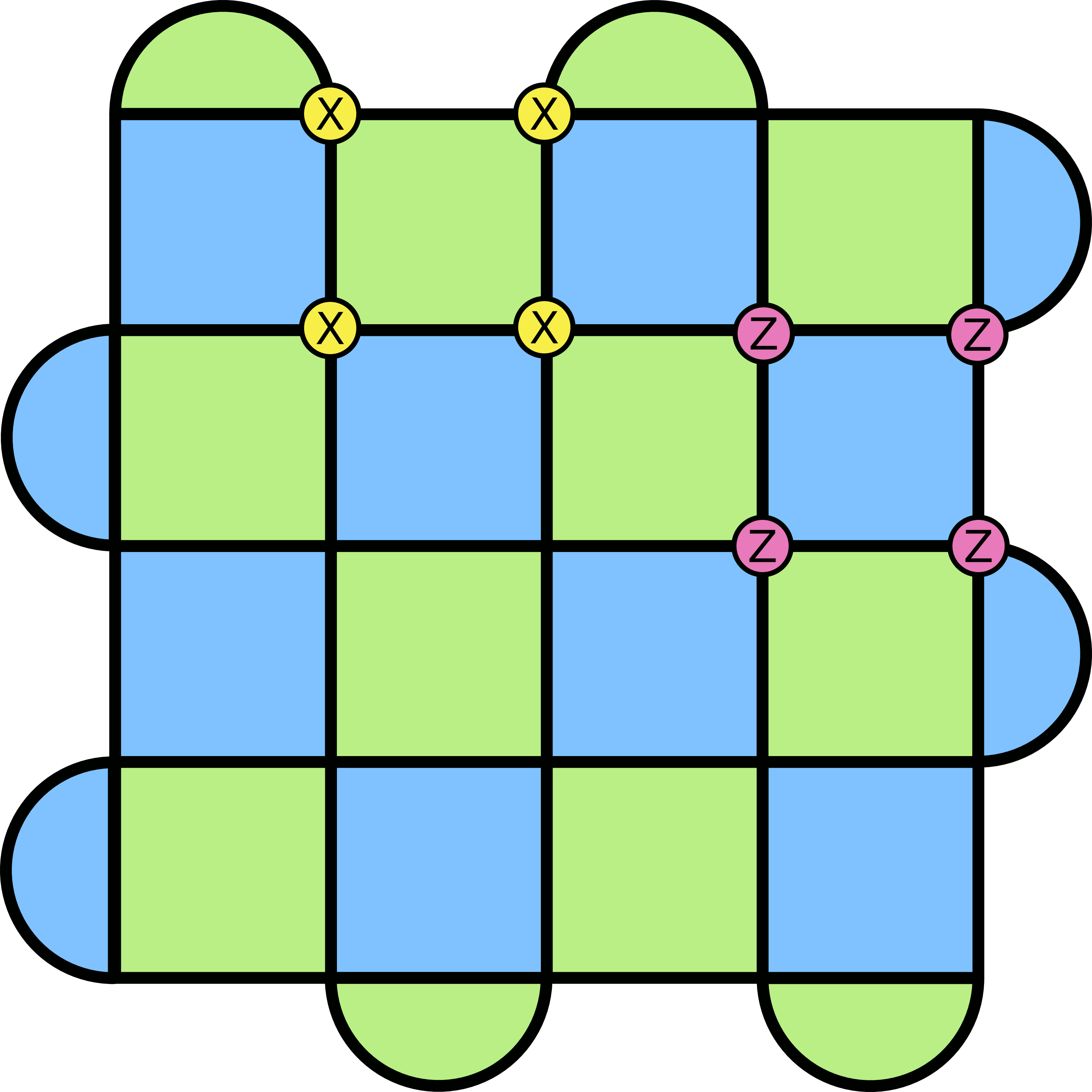
Then, it shouldn’t be too surprising that nothing goes wrong here. Since they are separated, it doesn’t matter what stabilizer we apply first. That’s because the two stabilizers won’t “interact”. Any Pauli operator on the first stabilizer will meet an identity from the second one, and since the identity commutes with everything, there’s no issue.
The more interesting case is when two stabilizers are adjacent, which means some of their operators do overlap:
Here, the situation looks more complicated, but not by much. First, because of the checkerboard pattern of the surface code, two adjacent stabilizers are of different colour. This means we have XXXX and ZZZZ (I’m dealing with the squares here, but you should convince yourself that the half-moon plaquettes work the same). These stabilizers are squares, which means exactly two operators will overlap. It’s always two, because the only alternative is one (where the squares are diagonal from each other), but this cannot happen because those types of arrangements are always with the same colour. The other operators can be freely moved like in the previous case. For the ones which overlap, the anticommutation relations will bring in a negative sign when we swap them.
But notice how many of these we have! There will always be two such pairs, which means we’ll have two negative signs coming out of the calculation. And since we all know that two negatives make a positive, the stabilizers will commute. So in fact, the entire group of stabilizers commutes. In the diagram above, this corresponds to swapping the overlap between X and Z circles (each swap gives a minus sign).
To finish things off, we define our quantum state to be in the ground state of some fictitious Hamiltonian H (see here3). Don’t worry if you aren’t familiar with the physics jargon. In our case, it just means that we want our quantum state to be the one in which all of the stabilizers have a +1 eigenvalue. Enforcing this will lead us to detecting errors, which are excitations or deviations from the ground state.
Parities and errors
I just finished saying that we want all of our stabilizers to have eigenvalue +1. What does that mean?
For our purposes, an eigenvalue is just a measurement outcome. These are implemented using helper qubits4 which essentially measure the eigenvalues of Pauli operators from the stabilizers. As an example, if I had a stabilizer of the form XXXX, the measurement would return me a value of (±1)(±1)(±1)(±1) = ±1, depending on the eigenvalue for each physical qubit it acts on.
You can see the binary arithmetic playing out here. Because of the way the stabilizer measures eigenvalues, we are always going to have a value of ±1 at the end. Furthermore, we can play a counting game on the plaquettes. If there are an even number of errors on a plaquette (0, 2, or 4), then the stabilizer’s eigenvalue when measured will be +1. On the other hand, an odd number of errors will mean −1 shows up an odd number of times in the product, giving an eigenvalue of −1. Since we are assuming that the surface code begins in its ground state with stabilizer eigenvalues of +1, we know that a measured eigenvalue of −1 means there are an odd number of errors that appeared on that plaquette. Sometimes, this is called a “violation” of a stabilizer.
To get a sense of this, the following are some examples of errors on the lattice, and how they show up with a flipped eigenvalue. The graphical approach is to place a red dot in the middle of the plaquette when there is an odd number of errors present on the lattice. When there’s an error present, I’ve drawn it with a corresponding yellow circle and an X. Note that there are both X and Z errors that can occur, but to keep the diagrams clear, I’m only looking at X. The situation would be similar with Z errors, except the red dots would now appear on the blue plaquettes (because those are defined with X operators).
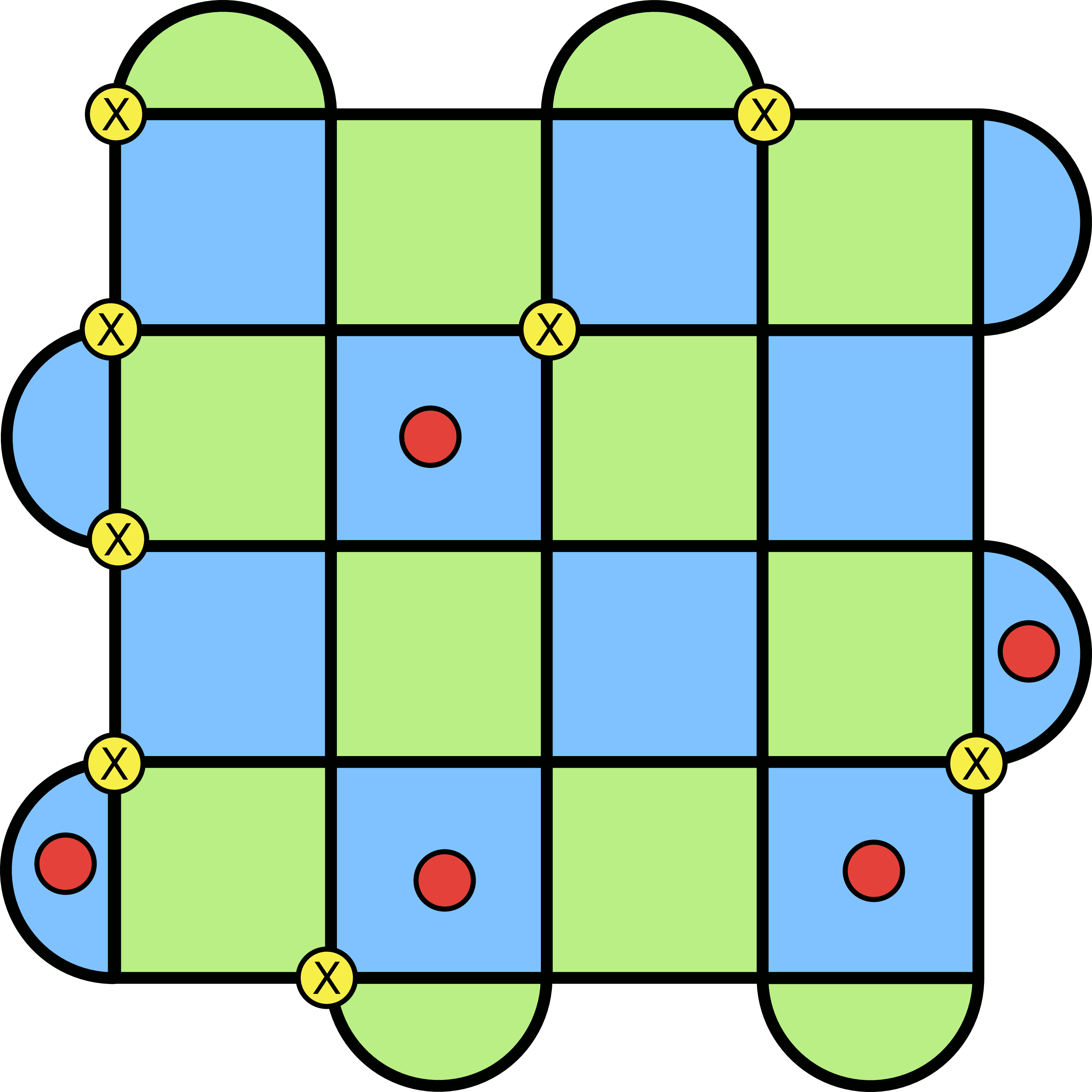
This gives us a way of detecting errors on the surface code. The state is protected if there are an even number of errors on a given plaquette, but it gets corrupted if we have an odd number of errors on a plaquette. If we go back to our handy repetition code, this is what happens when we send a message 000 and the recipient reads out 010. The state is corrupted, but it’s clear that something has happened to it (we detected an error). These errors are described using the idea of a syndrome, which is a vector that encodes which plaquettes have eigenvalue −1 (an odd number of errors).
I like to think of this vector as having a component of zero if the eigenvalue remains +1, and a component of one if the eigenvalue flips to −1. It doesn’t really matter what you use to denote it, as long as you can differentiate between a plaquette with a red dot and one without. Furthermore, I find it convenient to split the syndrome up into a part for the green plaquettes and a part for the blue plaquettes. So, if we were looking at X errors only, a syndrome could look like the example below. Again, this is just a convenient way to write it out (particularly when you’re writing code!). Also note here that there are black dots on each lattice site to indicate the physical qubits. This is just an artifact of how I was presenting things with the software. You can pretend like they aren’t there.
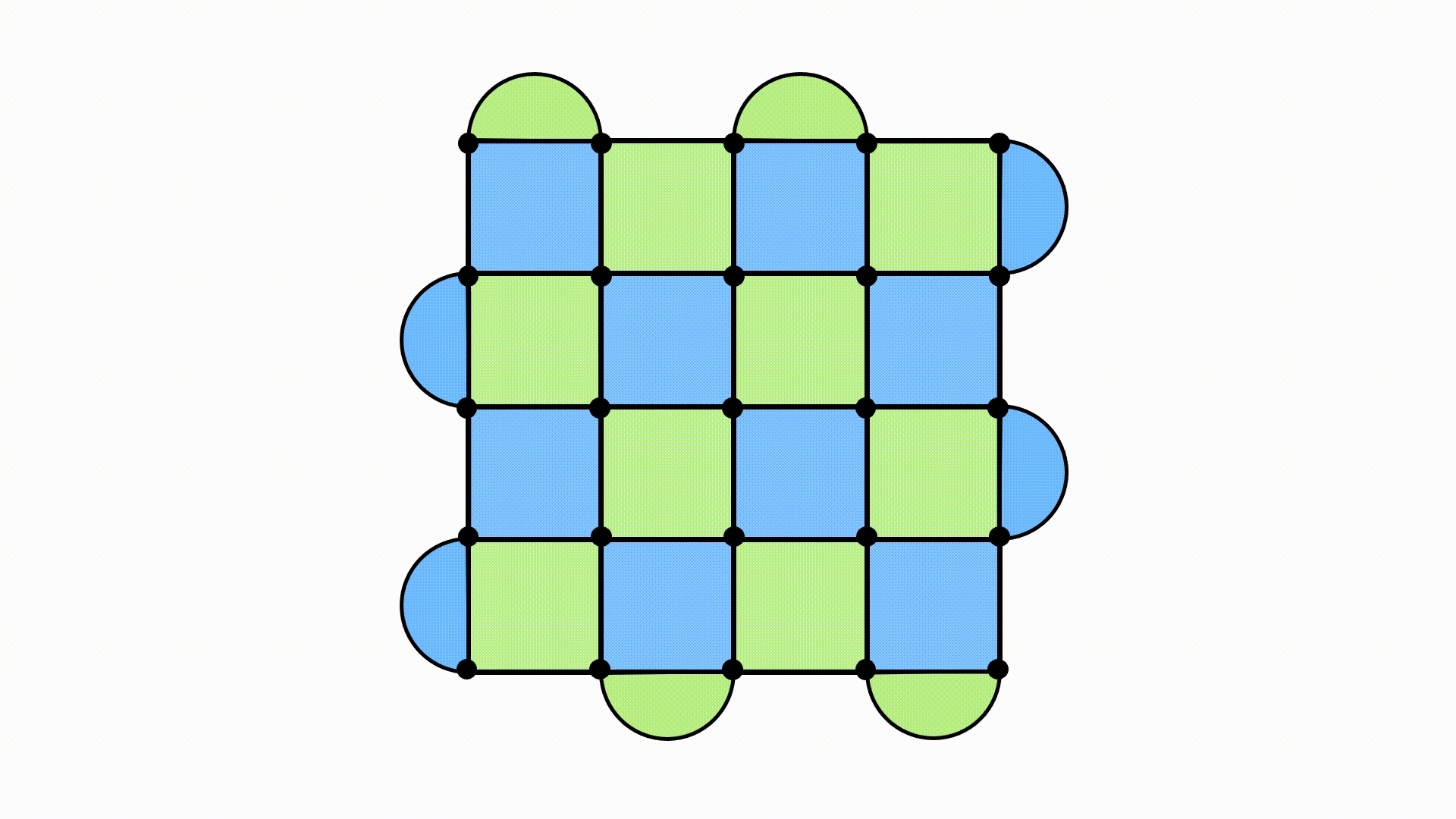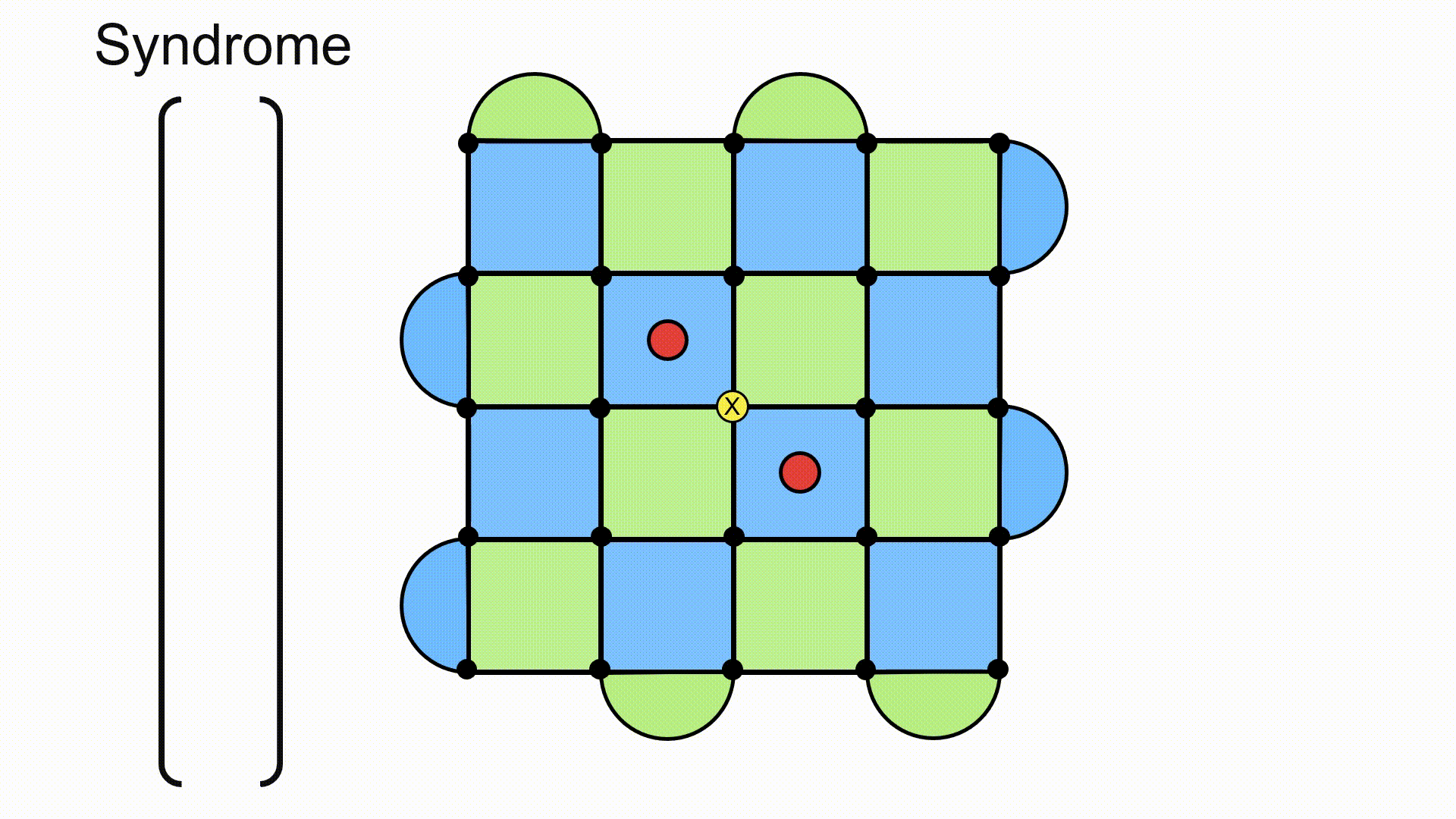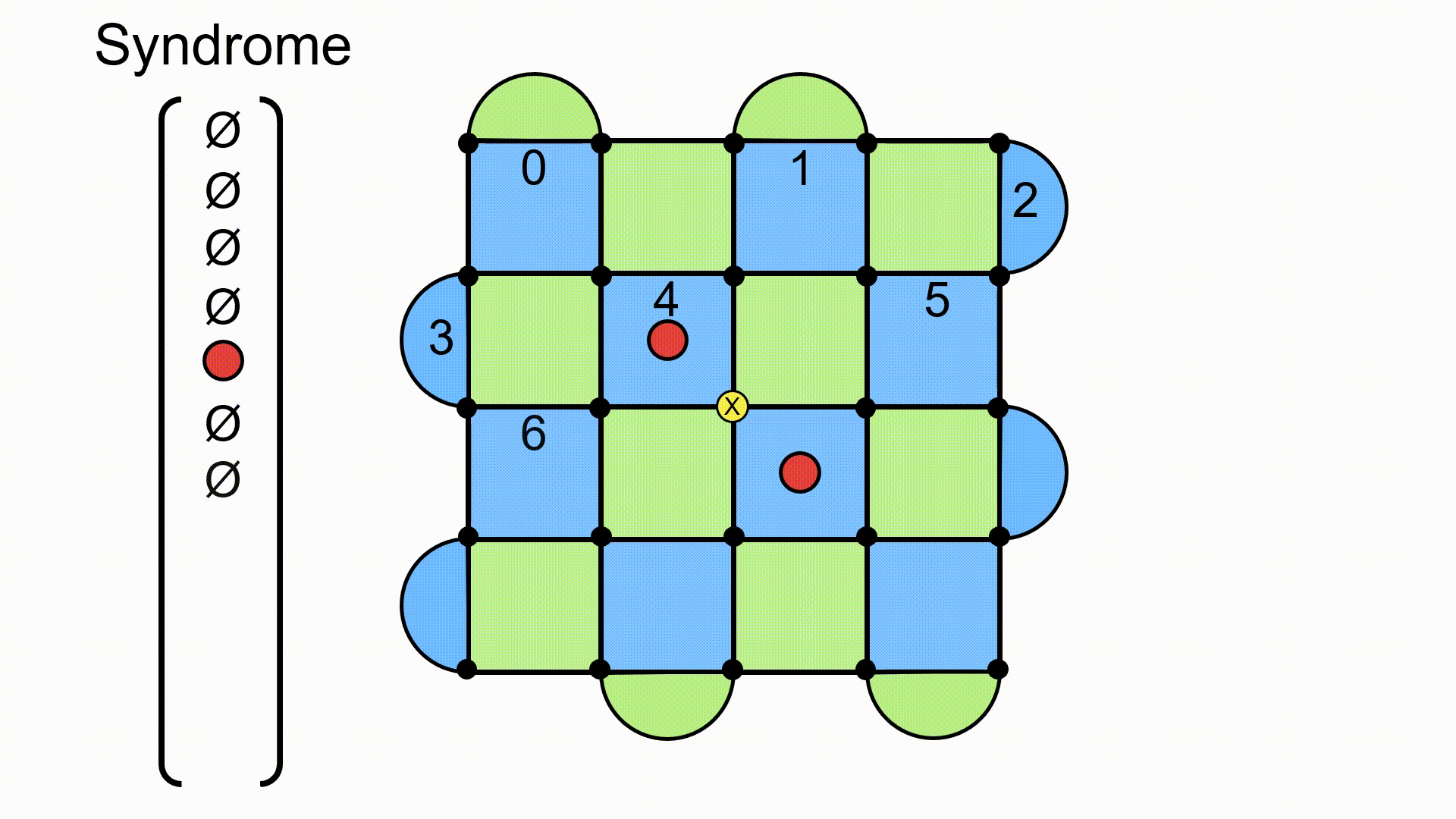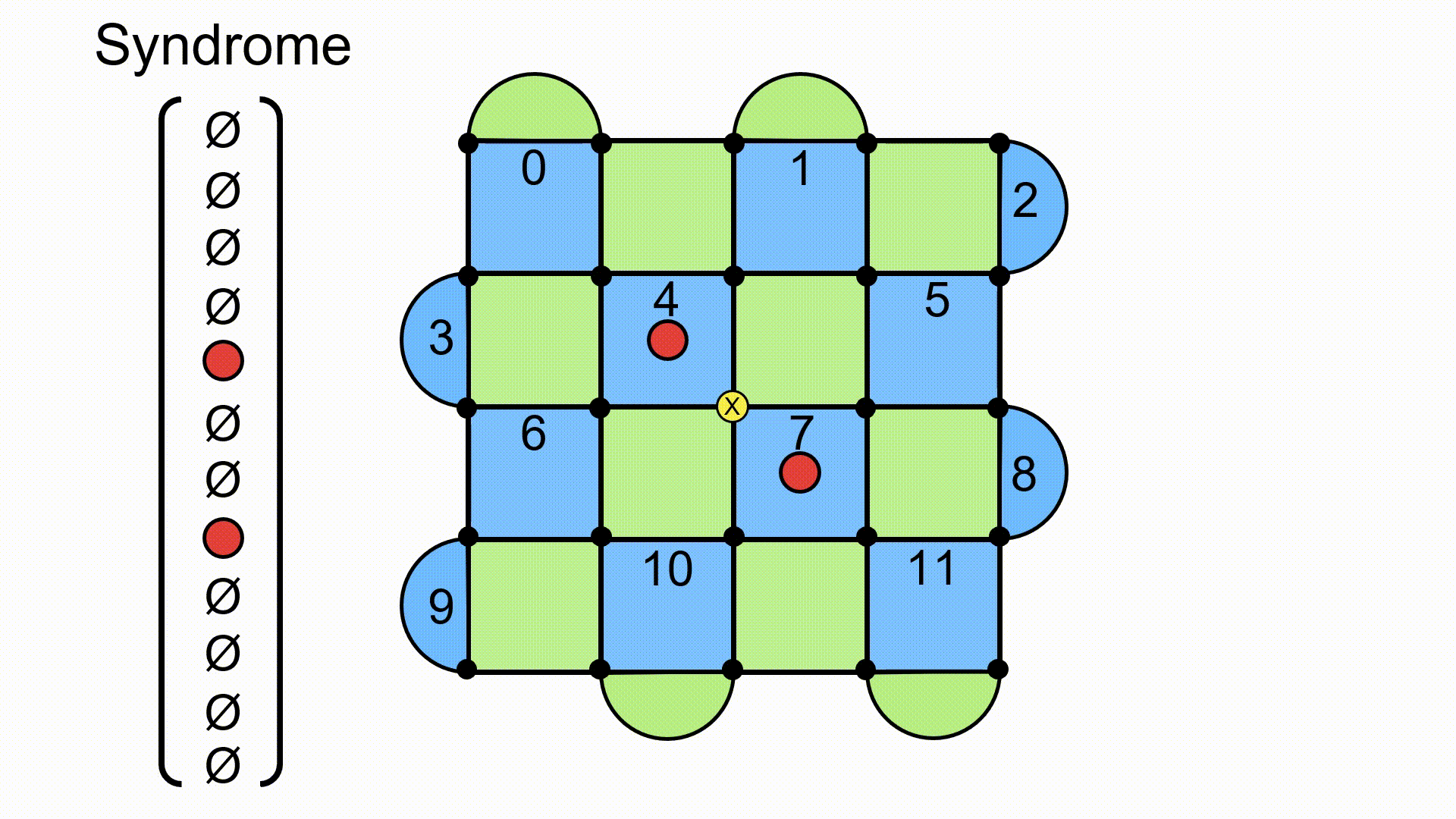
The game now is to figure out how to get our state back into the one that has no red dots (the syndrome goes to the zero vector).
Loops and states
Let’s say I give you the following error configuration of the lattice, with the corresponding syndrome.
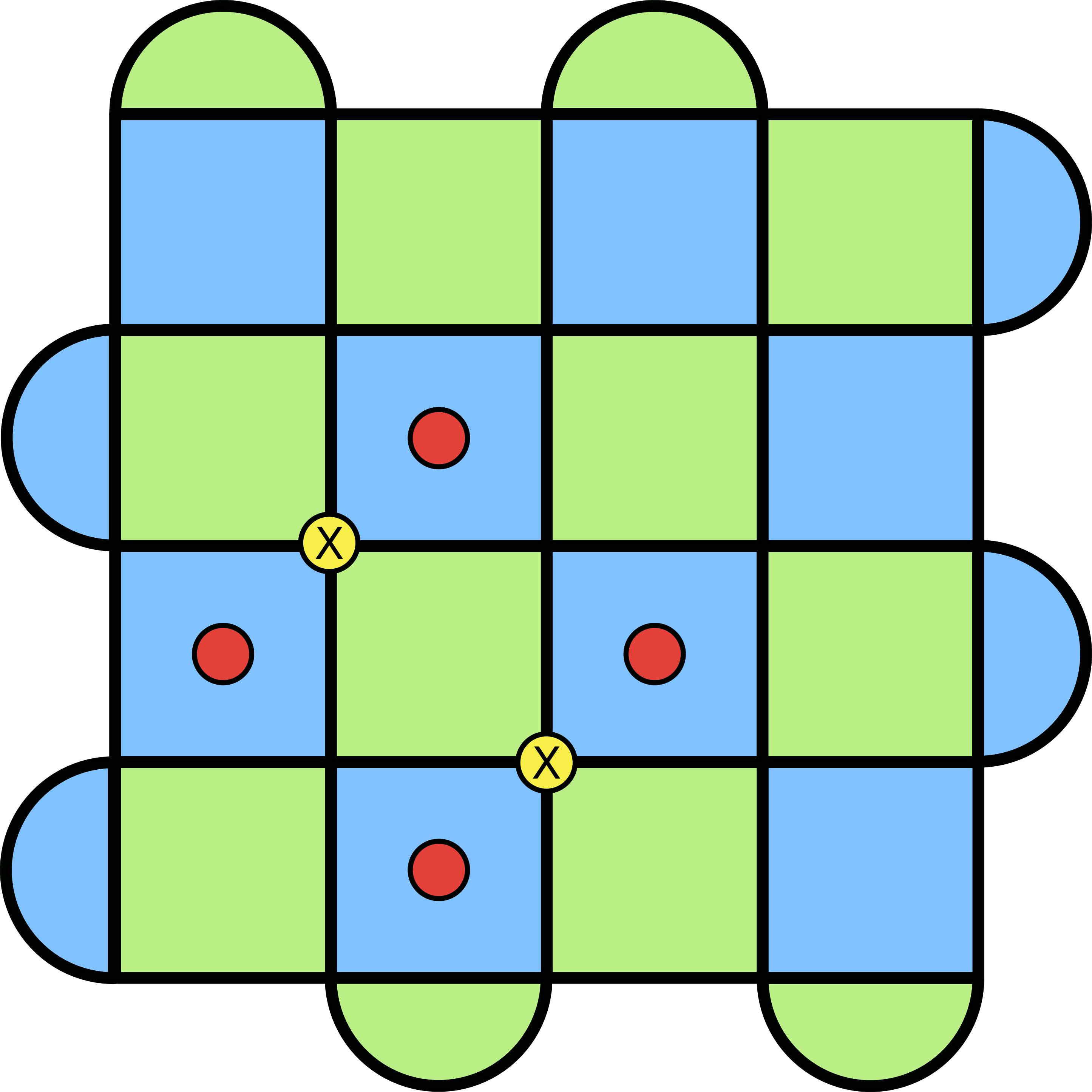
How can you apply Pauli operators to the lattice so that the red dots vanish?
If you’re familiar with the Pauli operators, you might have an answer: just apply the same configuration to itself! This takes advantage of the fact that the Pauli matrices are idempotent: they square to the identity. Applying X to a lattice site which already has an X error will give X × X = I. And voilà, correction complete!
That’s great, but there’s a small hitch: the error configuration isn’t available to you. That’s because you can’t directly measure the system (or else you could ruin the superposition it might be in). This is precisely why we introduced the stabilizers. They allow us to extract some information about the system without disturbing it from doing what it needs to do. So if you were a person working on a hardware implementation of the surface code, all you would see when you have errors is this.
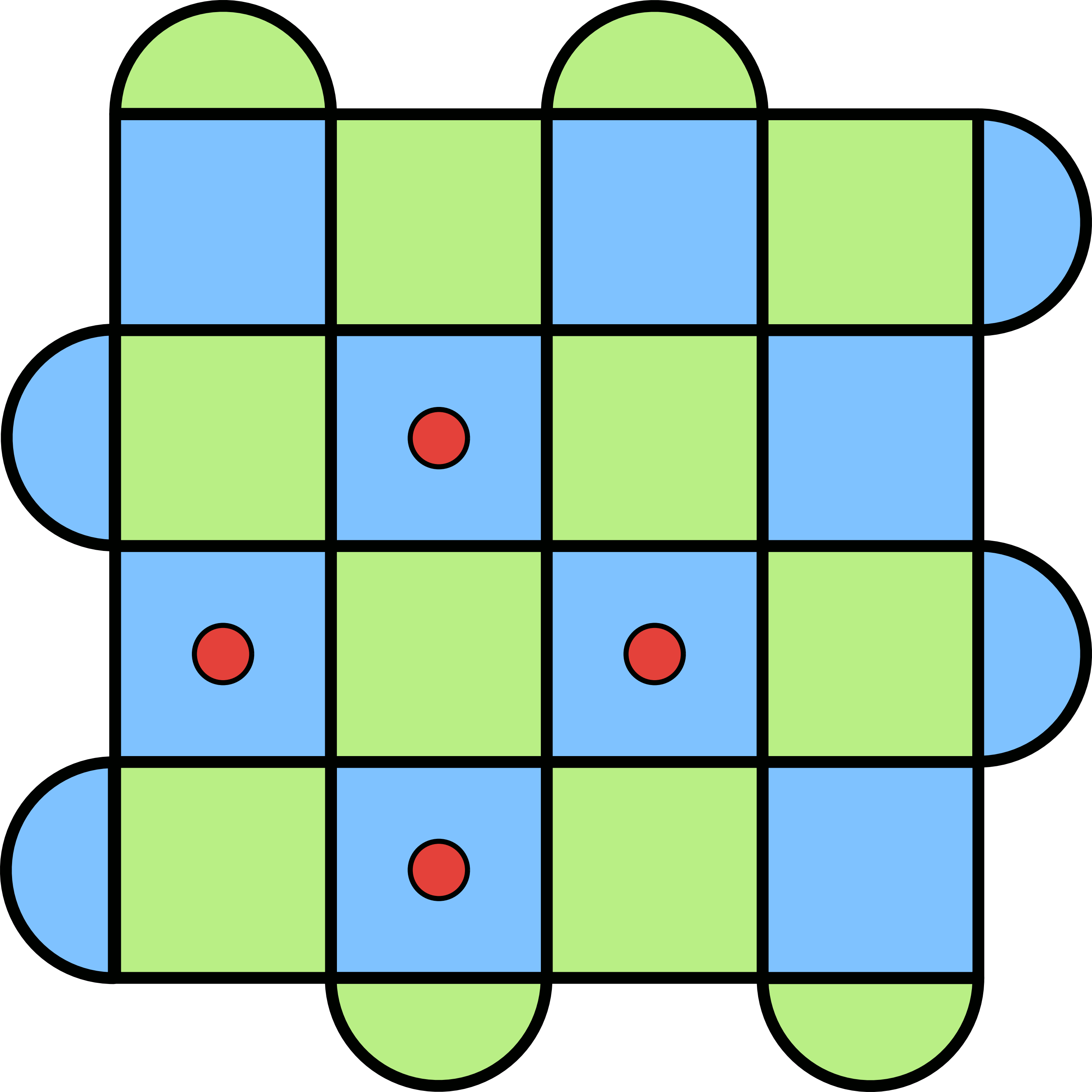
This is a bit inconvenient, since you don’t know exactly where you should apply the Pauli operators for corrections. Still, we saw above that all it takes to make a red dot disappear is to apply another error to that plaquette. This will change the parity of errors on the plaquette from odd (there’s a red dot) to even (it goes away). The issue is that applying an operator on most of the blue plaquettes does this:
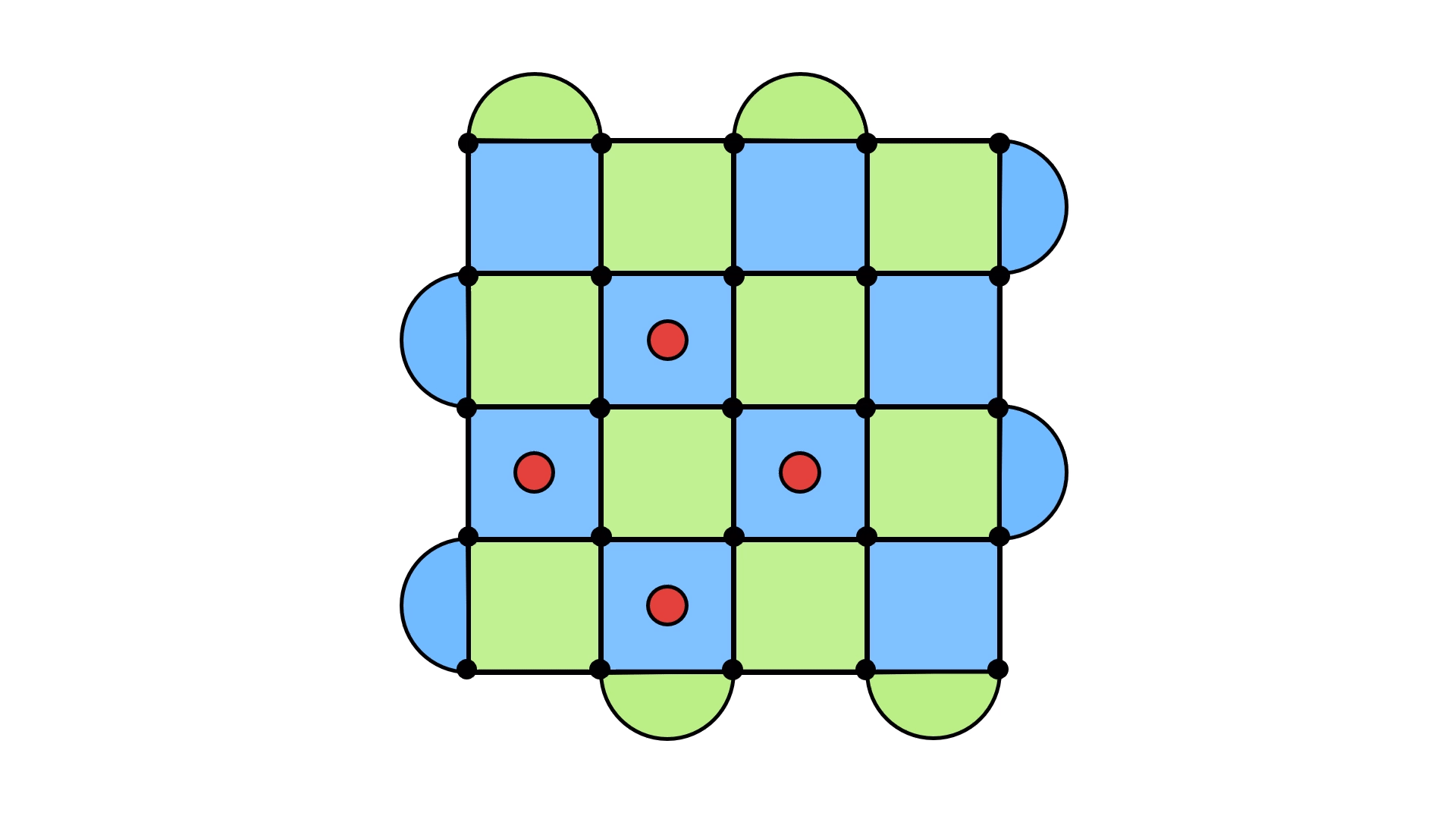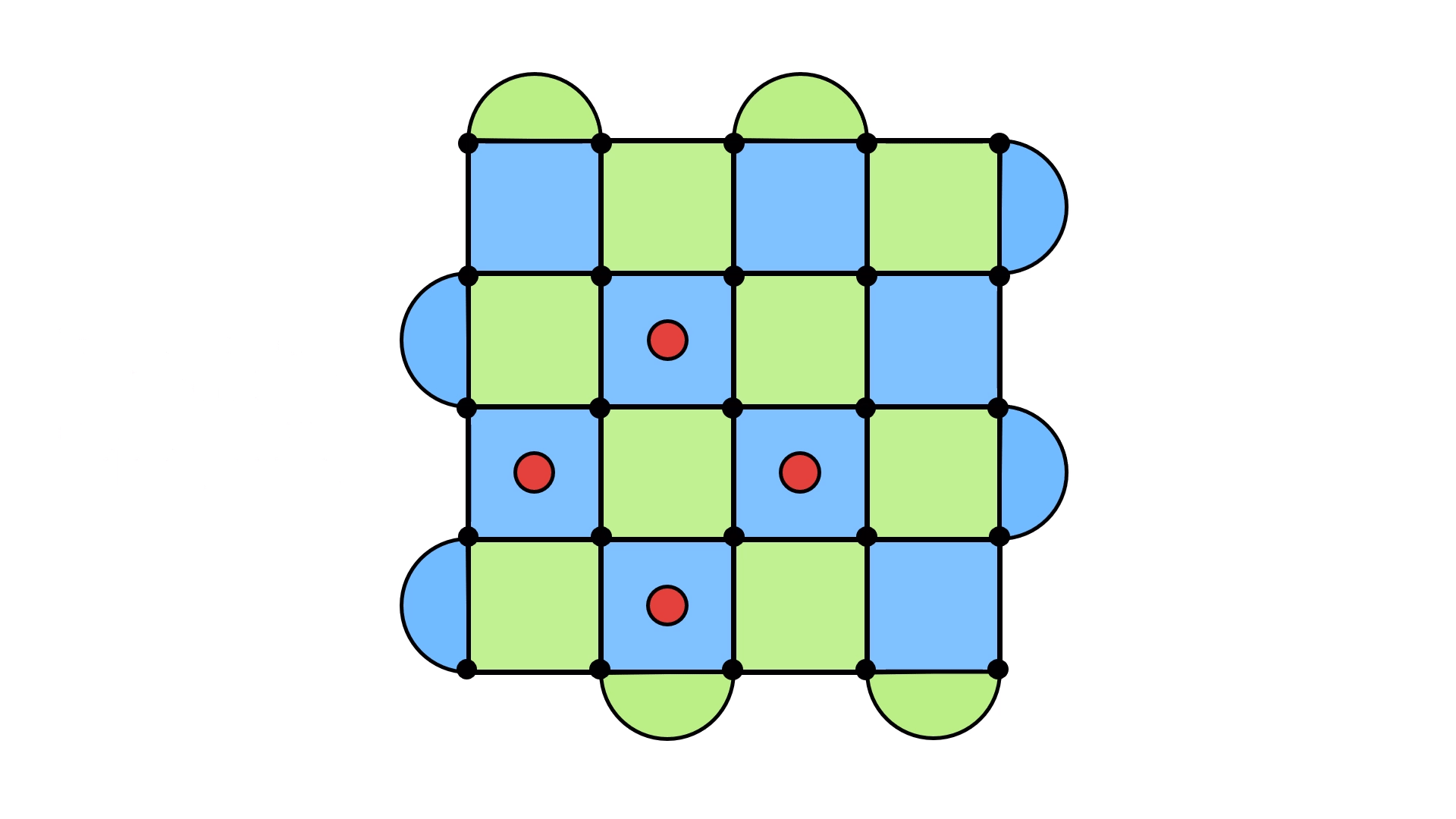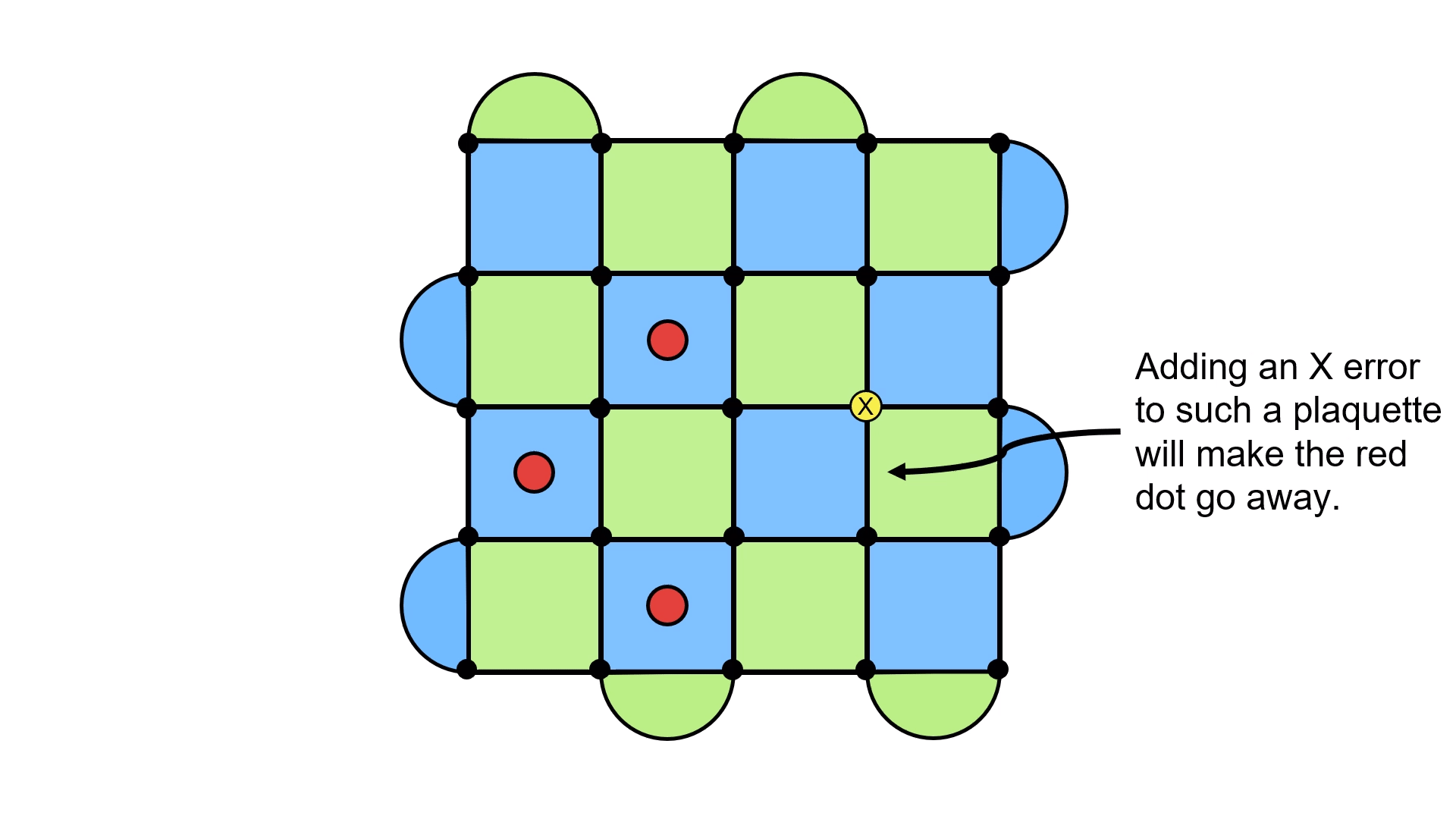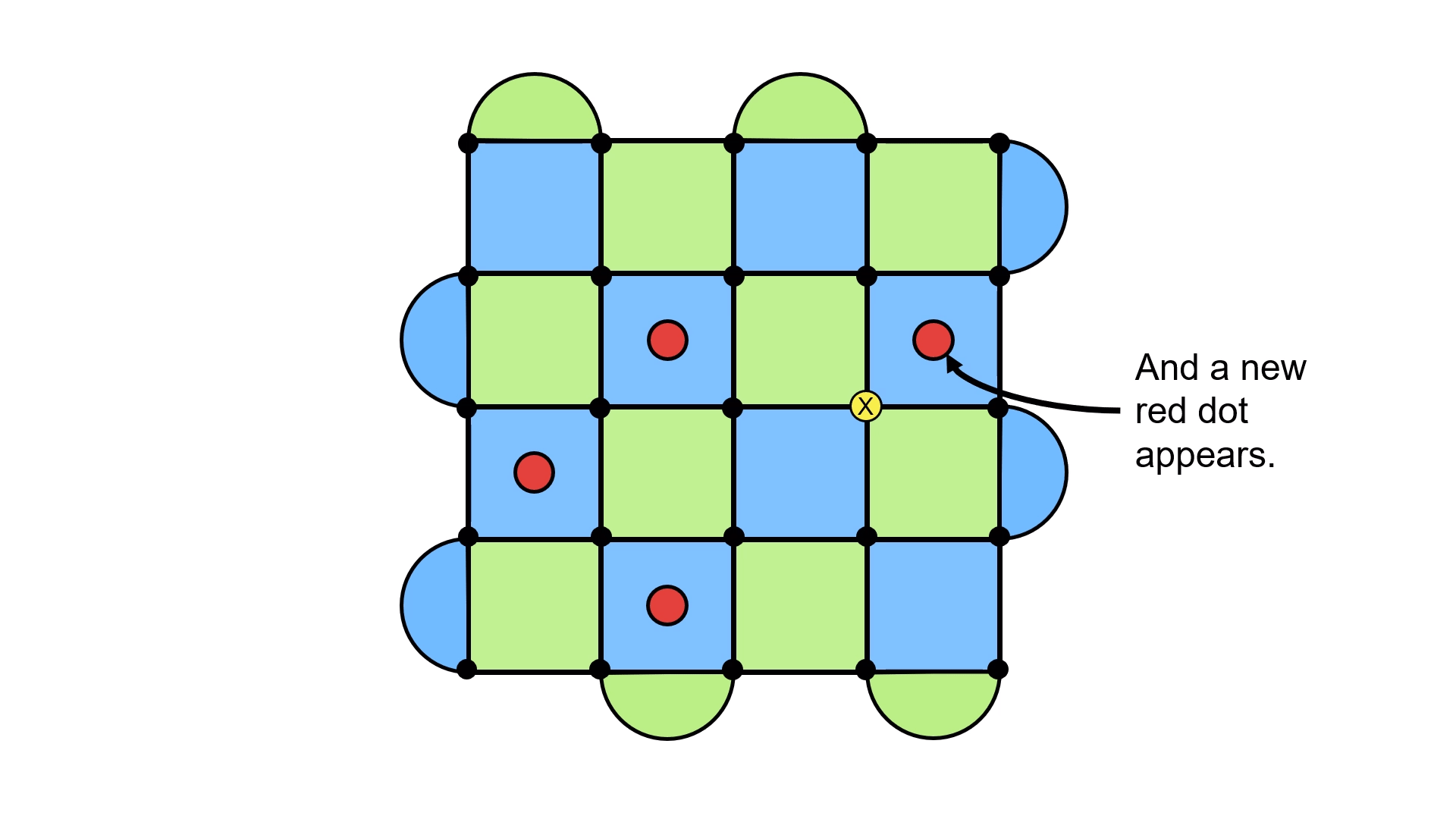
Sure, we got the error to go away, but we’ve just kicked it somewhere else! You can try to experiment a little, and you will see that this happens almost everywhere you look. Like trying to pick up a slippery object, the red dots will simply move away from you as you attempt to make them vanish.
You might have noticed that I said “almost everywhere”. It turns out that there are a few ways to make a syndrome go away without introducing more red dots in the process.
The first way is to remember our friends: the stabilizers. Applying these in groups can give us a clue about what we should do. Remember, the goal is to make the syndrome vanish (this is what I’m calling the syndrome with all-zeros as components), and we know that applying stabilizers to the ground state also doesn’t change the syndrome. So if we can take our error configuration and apply more errors to it such that the result is something that we can equally achieve with a bunch of stabilizers, than we’re in business. Remember, we can’t actually see the error configuration in practice, but it’s useful when analyzing the various scenarios.
Let’s take a bunch of stabilizers and apply them in one big clump to the lattice. Look what happens to the error configuration, remembering that applying the same operator on a site twice means it vanishes.
Look at those chains form! The overall error configuration becomes a loop, with all of the sites inside having the same operator applied to them twice (giving the identity). This means that one way to correct the errors is to form a closed loop. The syndrome will vanish (because it means that the error + recovery configuration is just a product of a bunch of stabilizers).
This looks promising. In fact, you might exclaim that we’re able to correct every kind of error that can occur, as long as we form loops. One thing to keep in mind though is the following: for the surface code, the syndrome isn’t unique to one kind of error5.
Say we have our familiar syndrome.
With a bit of work, you might come up with an error configuration whose syndrome matches the one above. The problem is that with a little more work you could find another one (and many more). Here are just two examples.
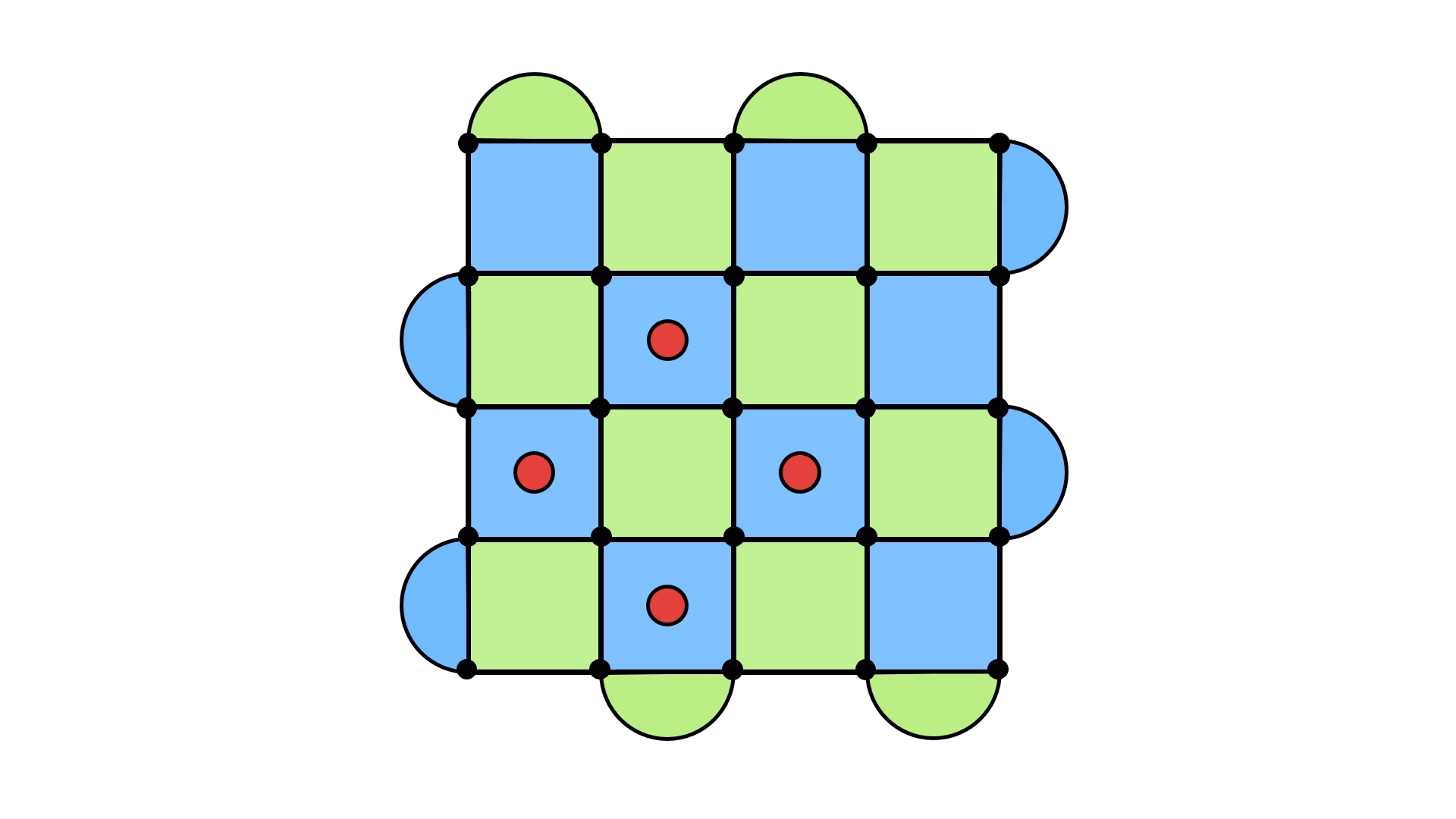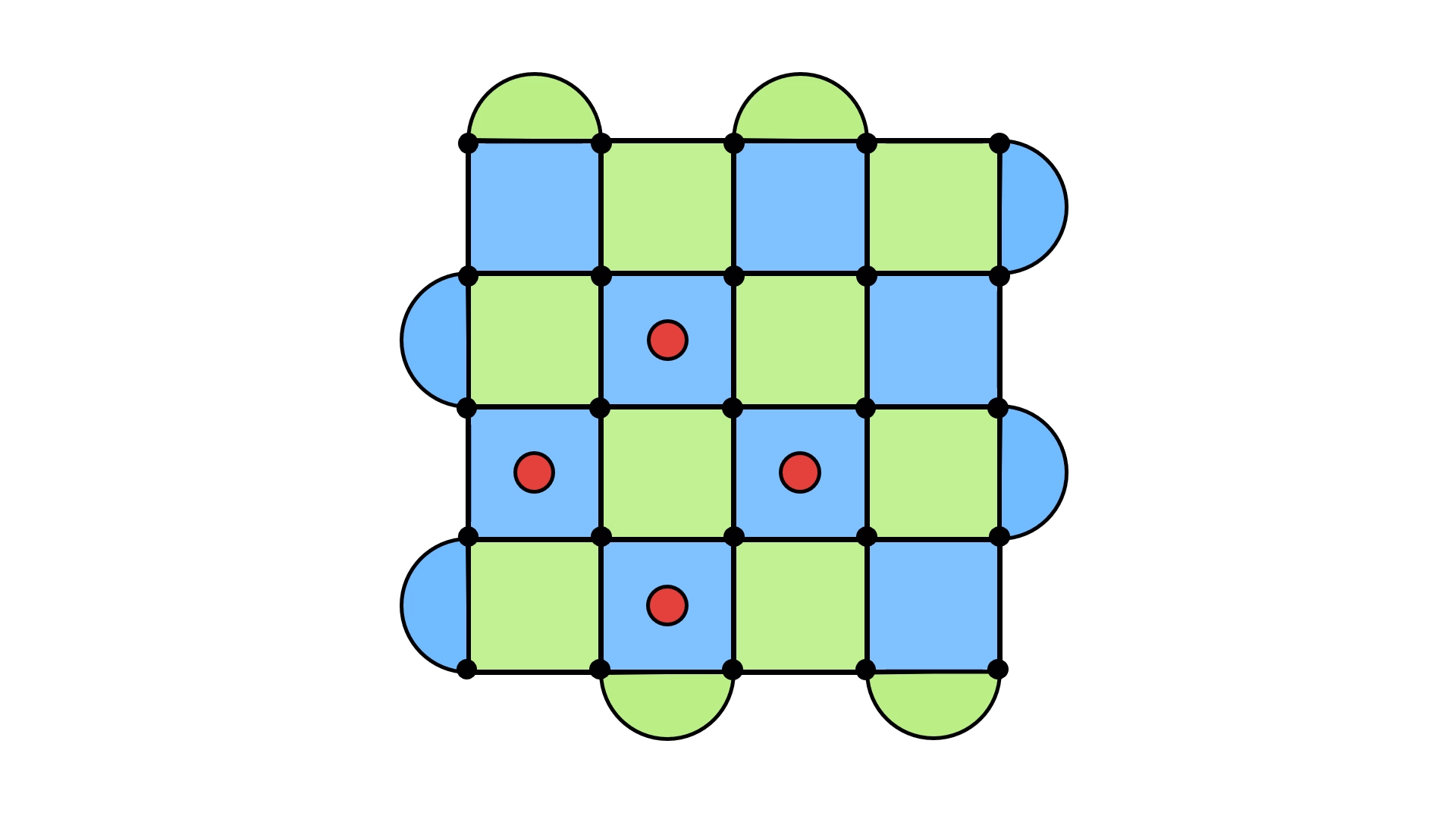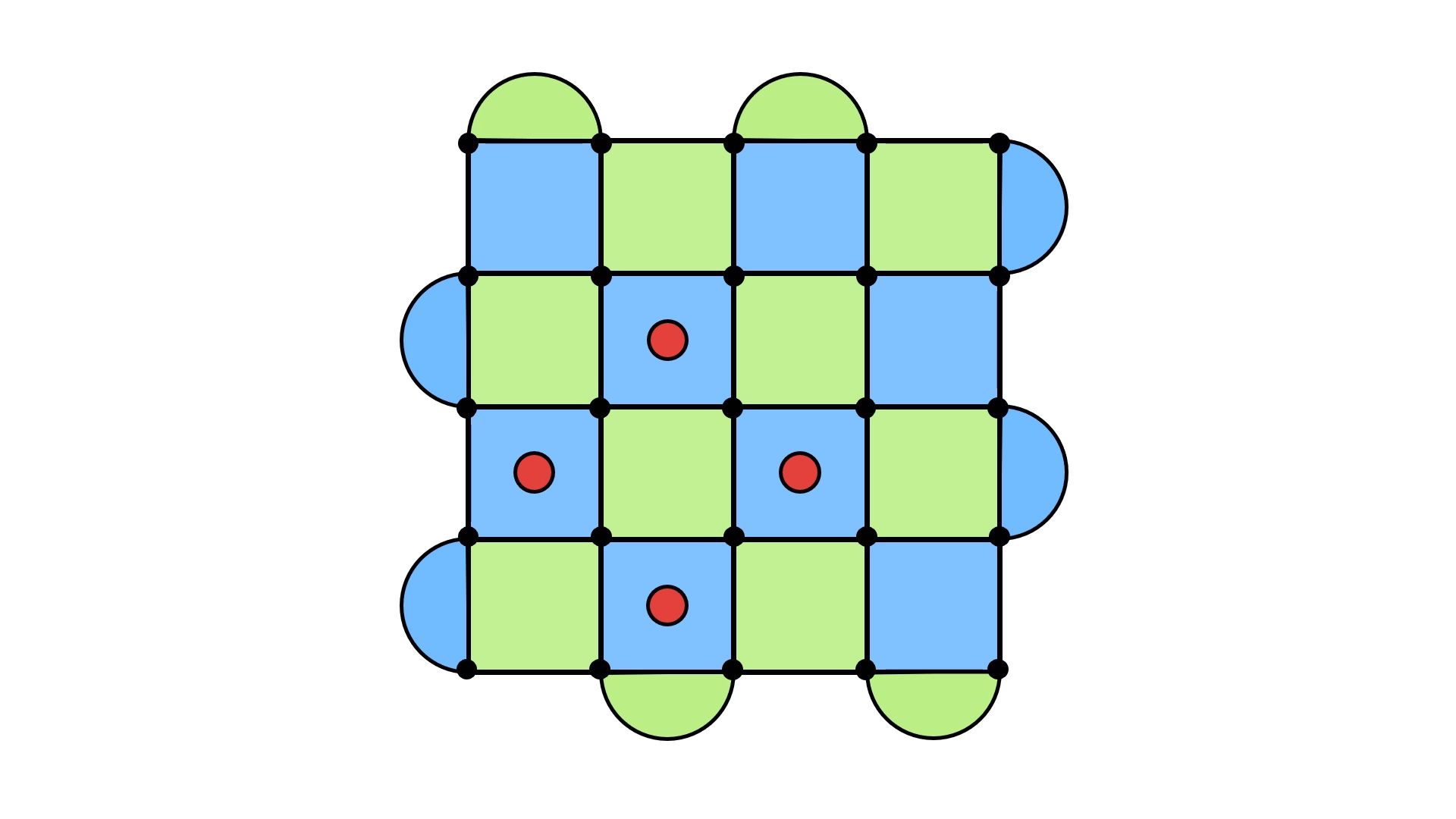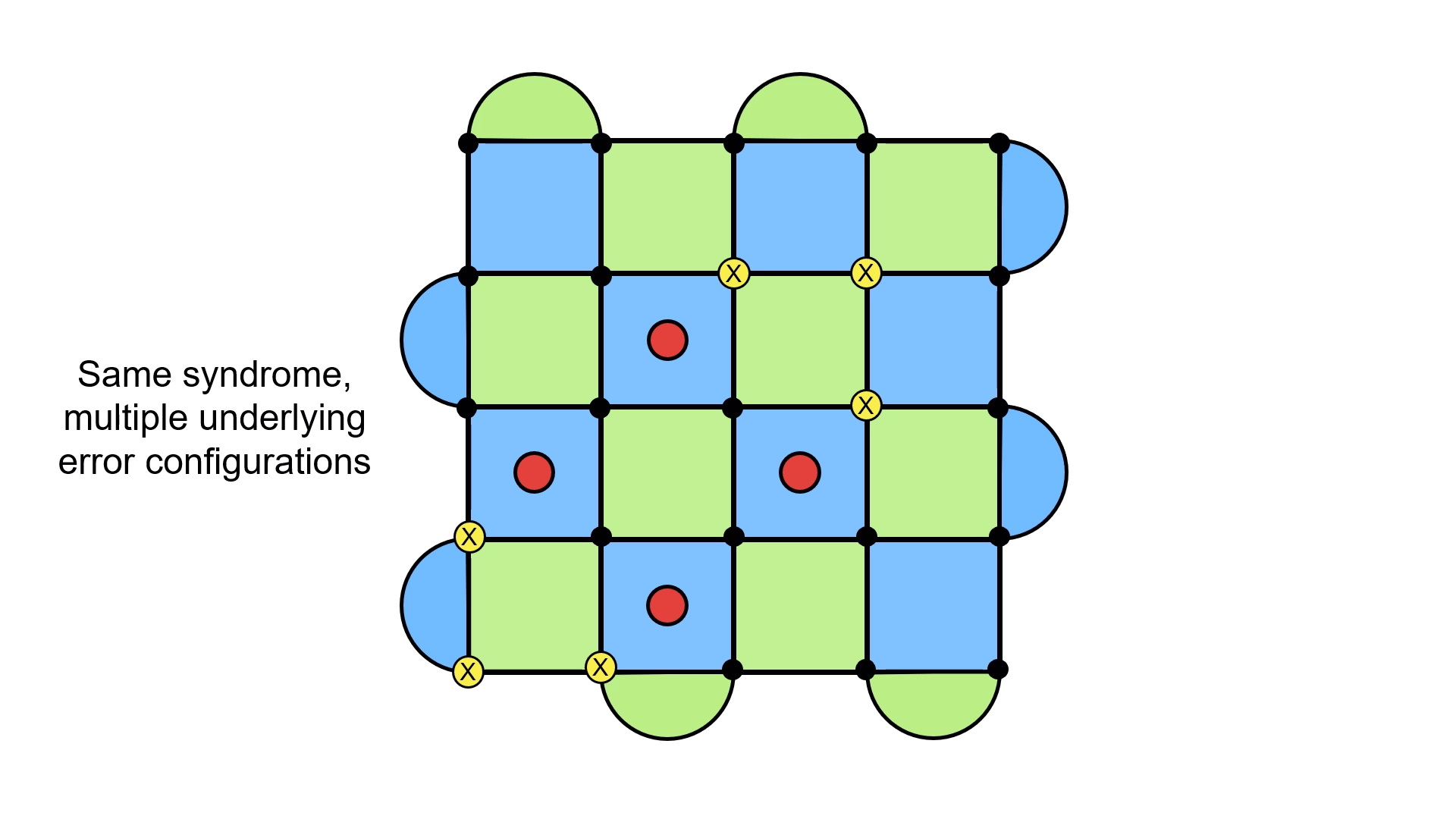
This means applying errors to get a loop depends on the error configuration you’re dealing with and not just the syndrome. But you only have access to the syndrome!
“Big deal,” you might say. “Who cares if I identify the right error? As long as the syndrome goes away, I’m good to go.”
And that is where we run into more trouble.
Logical operators
Despite the neat argument of parity for detecting errors, it turns out that this isn’t foolproof. That’s because the space carved up by the stabilizers doesn’t totally cover the list of operators which give no syndrome. There are some which aren’t a combination of stabilizers (or else they would belong in the group) and don’t show up when we check for errors.
This is both a good and a bad thing. It’s a good thing because having these other operators lets us manipulate our quantum state to do a computation. If we didn’t have them, we would be stuck with simply storing a quantum state. On the other hand, it’s bad because suddenly there ways to return back to a ground state that is different than the one we started with. While that’s good if we want to do a computation, it’s bad if we accidentally go into that state without knowing it. Worse, there’s no way we can know it, since we would have to know the original underlying state.
The idea is as follows. When you build a stabilizer code, the stabilizers are there to detect errors. But there will be operators that are not written as a product of stabilizers yet still commute with the stabilizers. They will go undetected if they get applied to your system, where “undetected” means the syndrome will be zero.
But remember our discussion above. When we were trying to build loops to make the syndrome go away, I mentioned that there are multiple underlying error configurations that give rise to the same syndrome (it’s not a one-to-one pairing). The problem is that applying the same recovery sequence to two different error configurations which have the same syndrome can make these other operators appear.
Let’s see this in action. Below, I’ve shown a syndrome, we well as the errors we applied to make the syndrome go away.
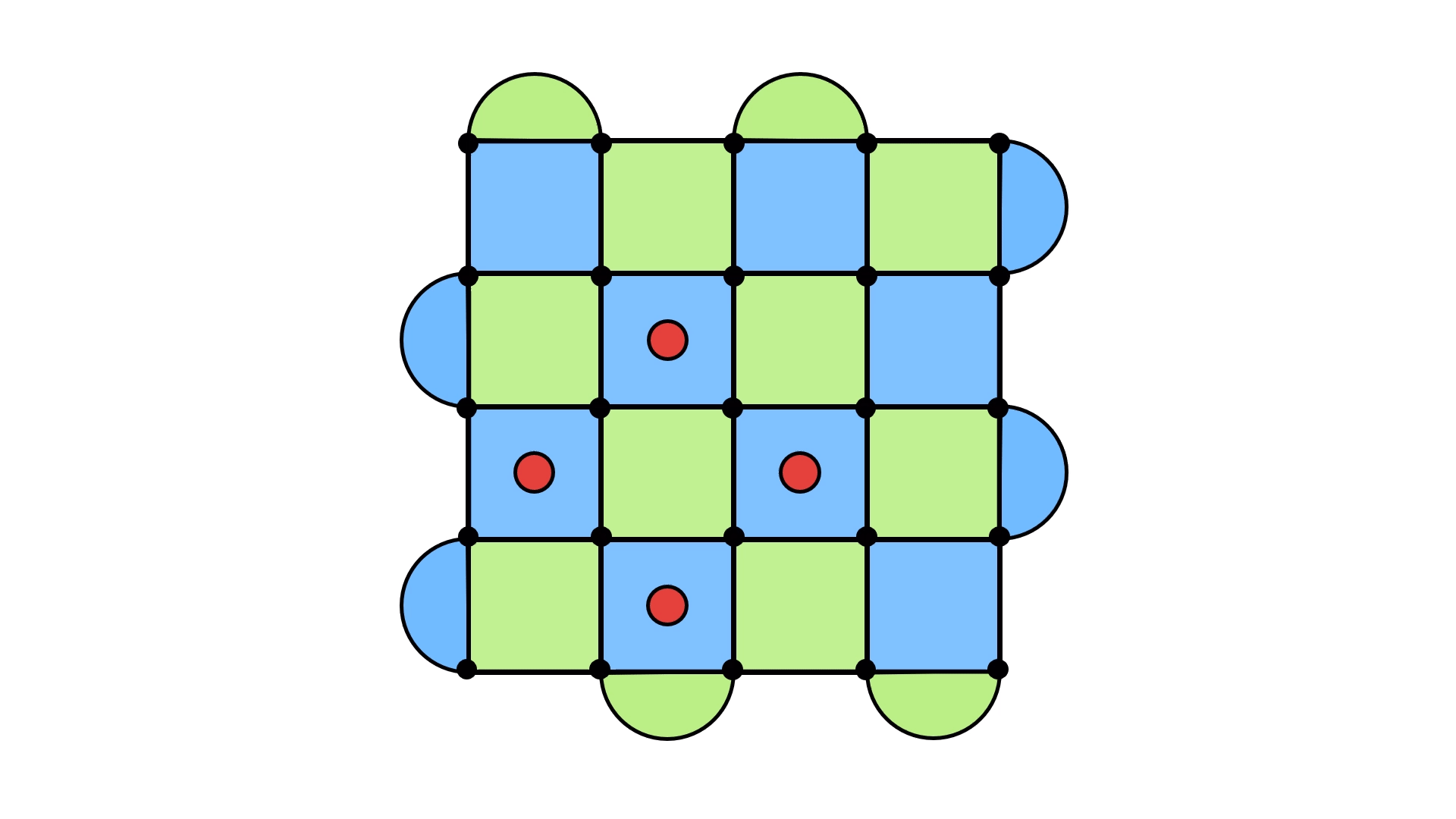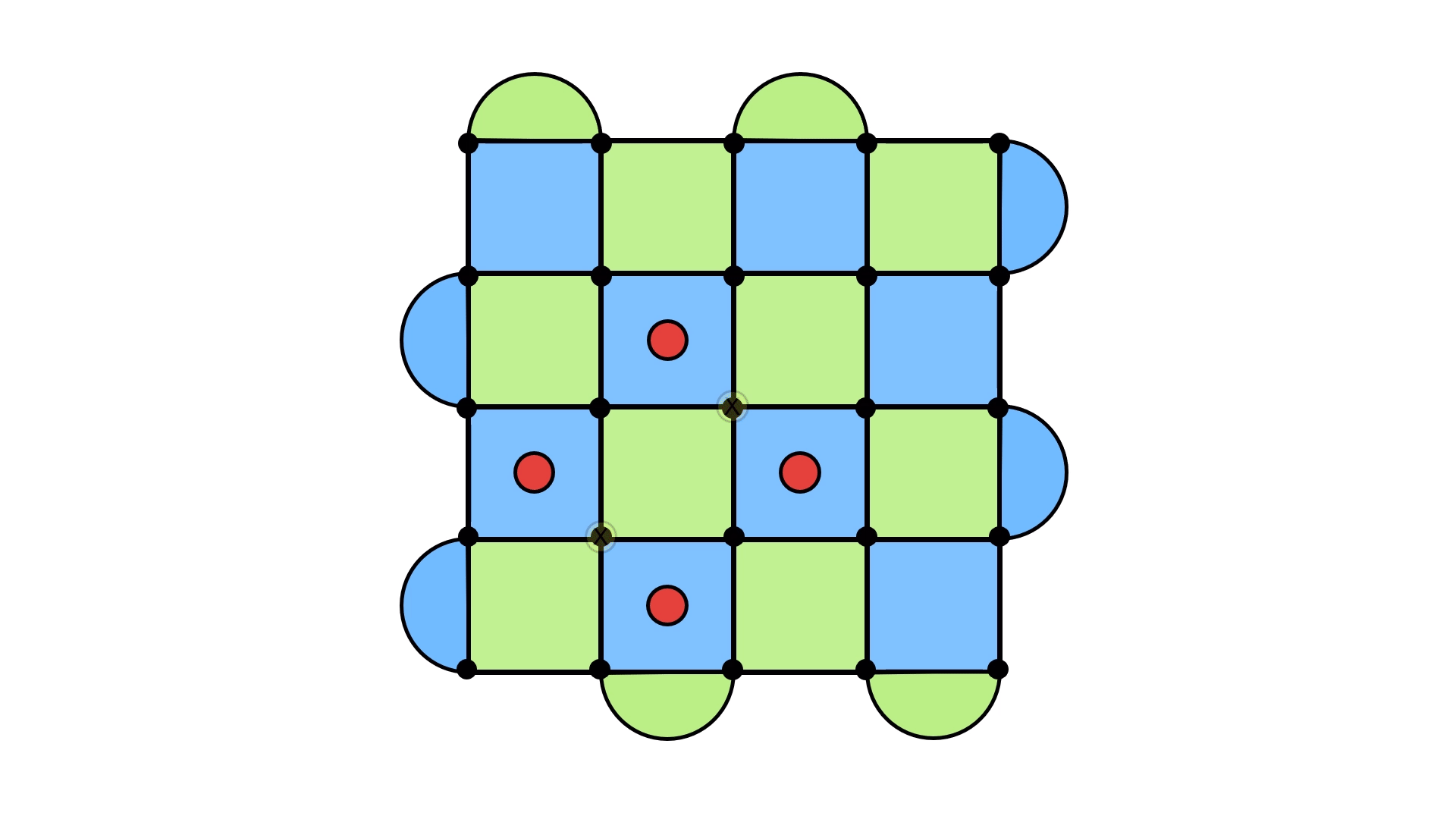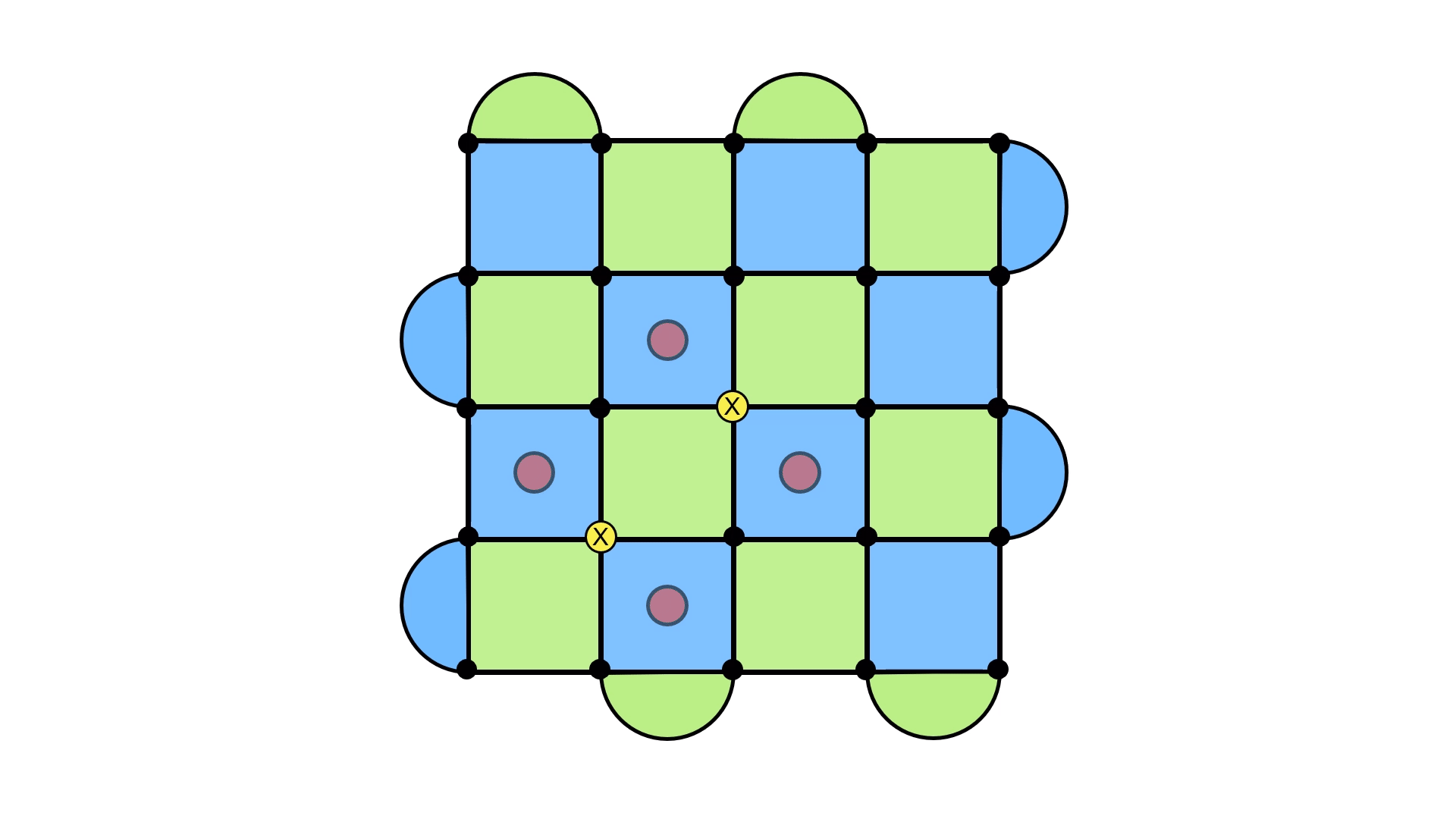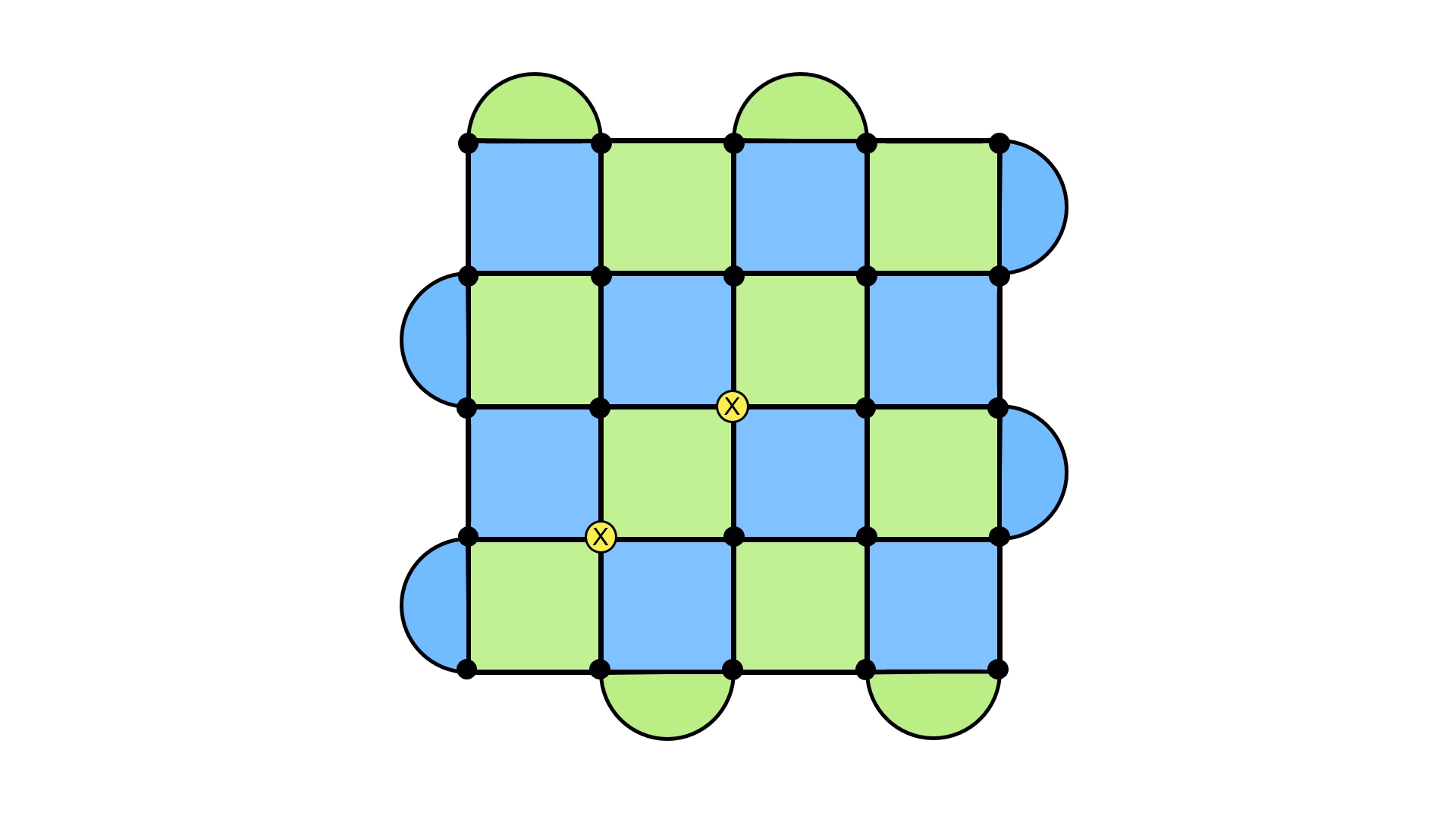
Now here are two potential underlying error configurations, and the result of applying the recovery configuration.
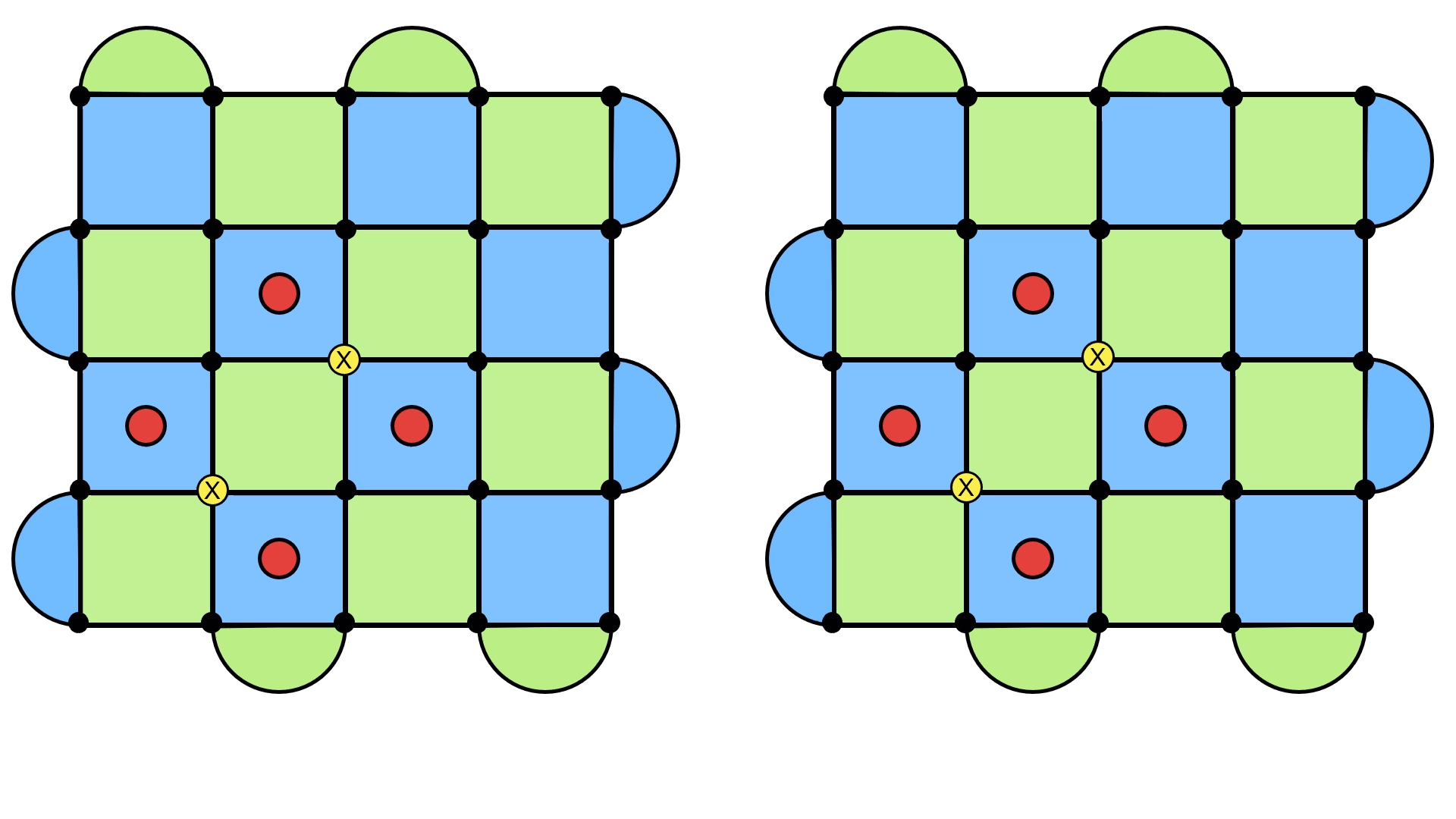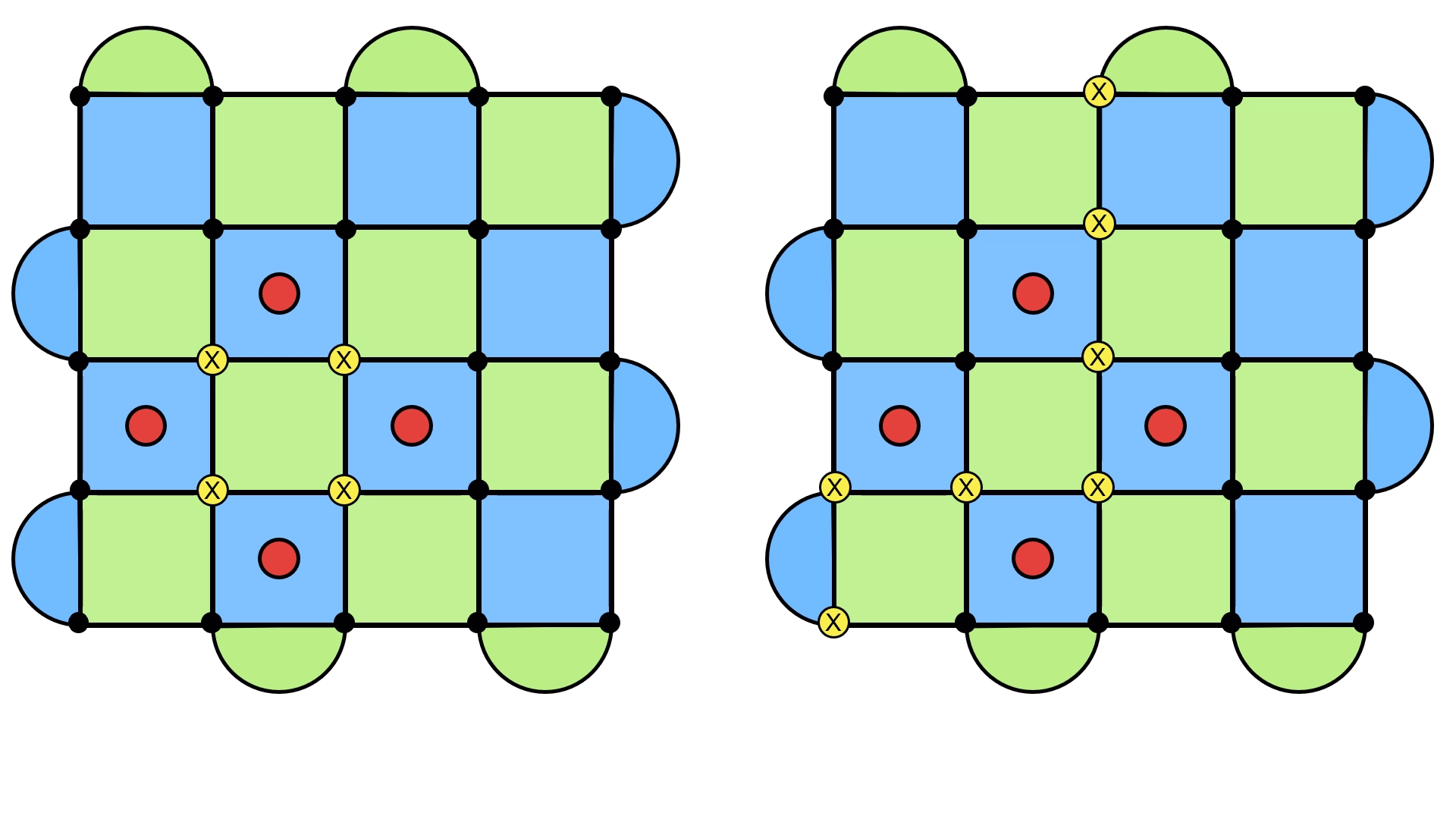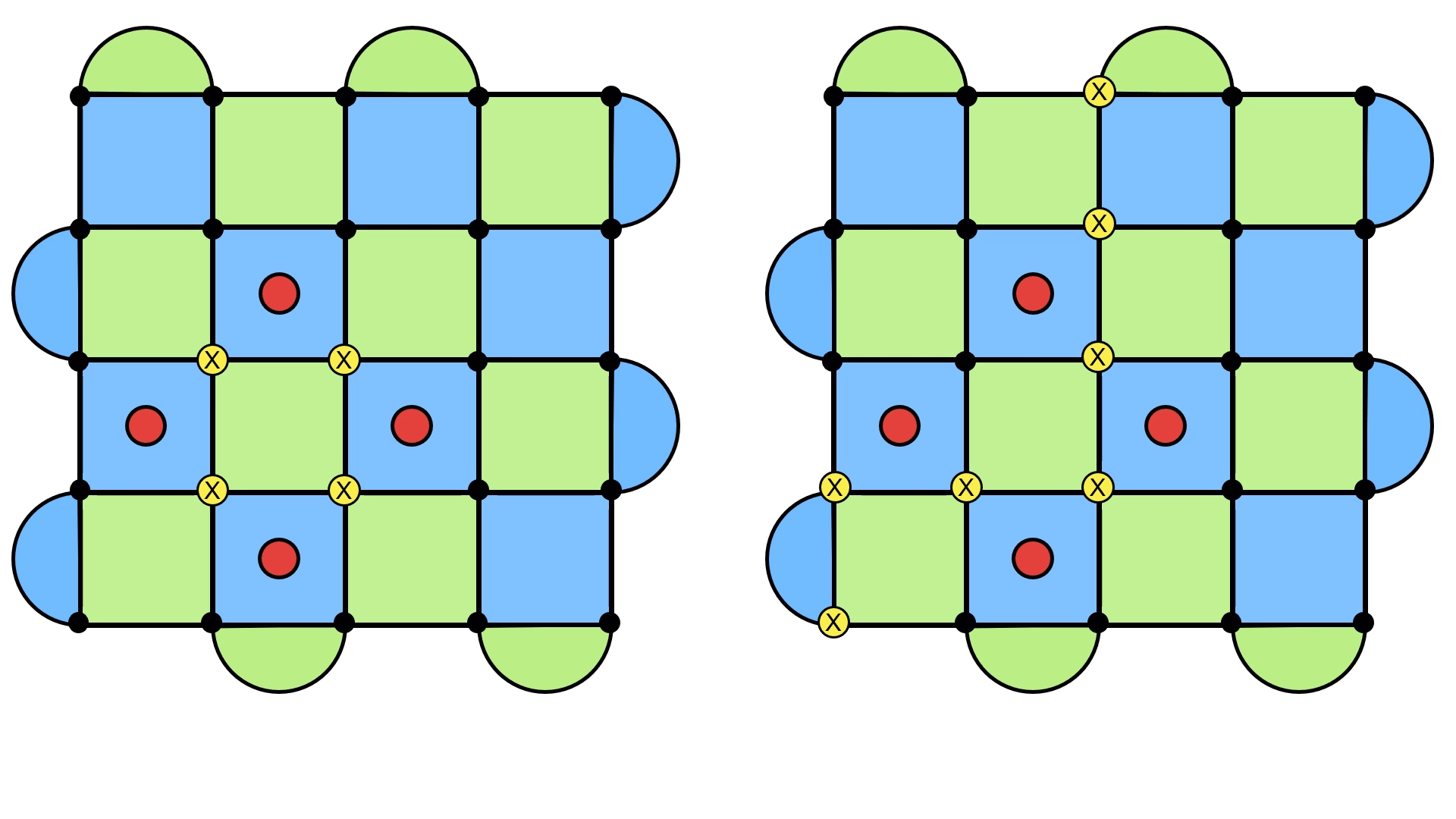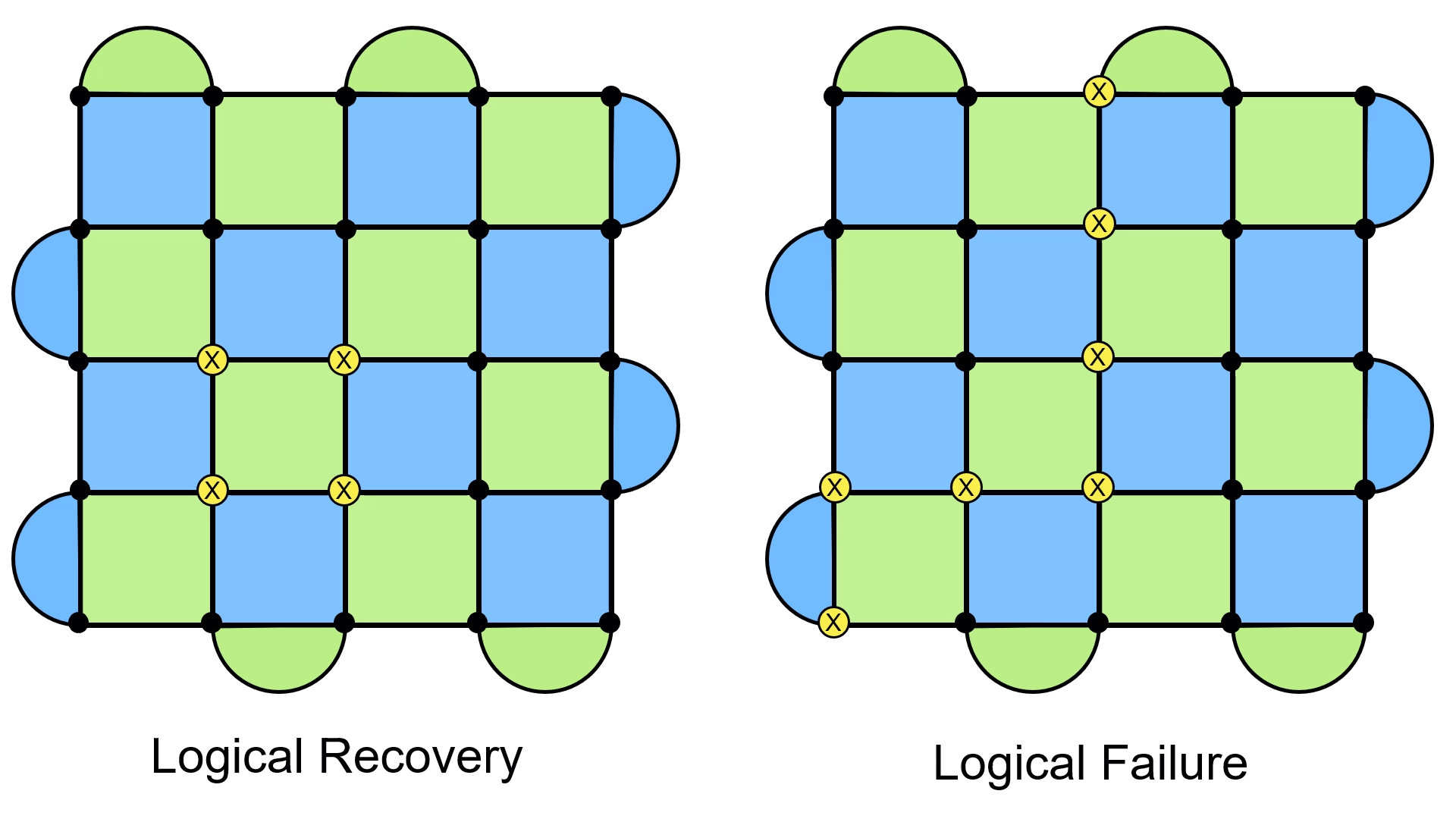
On the left, we see the error + recovery configuration forming a loop, just as we expect. But on the right, something strange happens. Instead of forming the usual loop, it forms a loop that doesn’t close in on itself and stretches across the entire lattice. I like to think of it as still being a loop, except now it wraps around the surface code (think of a rubber band holding a deck of cards together).
The point is that this is a very different kind of loop. There are fancy mathematical names for this6, but the key idea is that this loop cannot be written as a product of the stabilizers, and is exactly the kind of object which commutes with them. This means the they won’t get detected with our quantum error correction scheme of returning the syndrome to a bunch of zeros, and they bring our quantum information into a new state.
Here’s how.
The tool we use to calculate if a loop has been placed sometimes goes under the name of a “Wilson Loop”. The idea is that this operator can detect if a chain of errors has crossed the lattice, bringing us into a new state.
I’ll focus on the X errors, but the same is true for the Z errors (though they are oriented along the other direction of the lattice). The boundary conditions of the lattice ensures that a chain of X errors going from the bottom to the top will not cause a syndrome. It’s worth pausing for a moment to digest this. Any time we place an X error, syndromes will pop up. But, because of the half-moon plaquettes being only one colour along a given boundary, placing an X error at the top, for example, won’t cause any of the half-moon plaquettes to get a red dot. The same is true for placing X errors at the bottom. Therefore, if we connect those two errors by making sure each blue plaquette is covered by two X errors, we’ll be fine. The Z case is the same, except that now we have to go horizontally across the lattice.
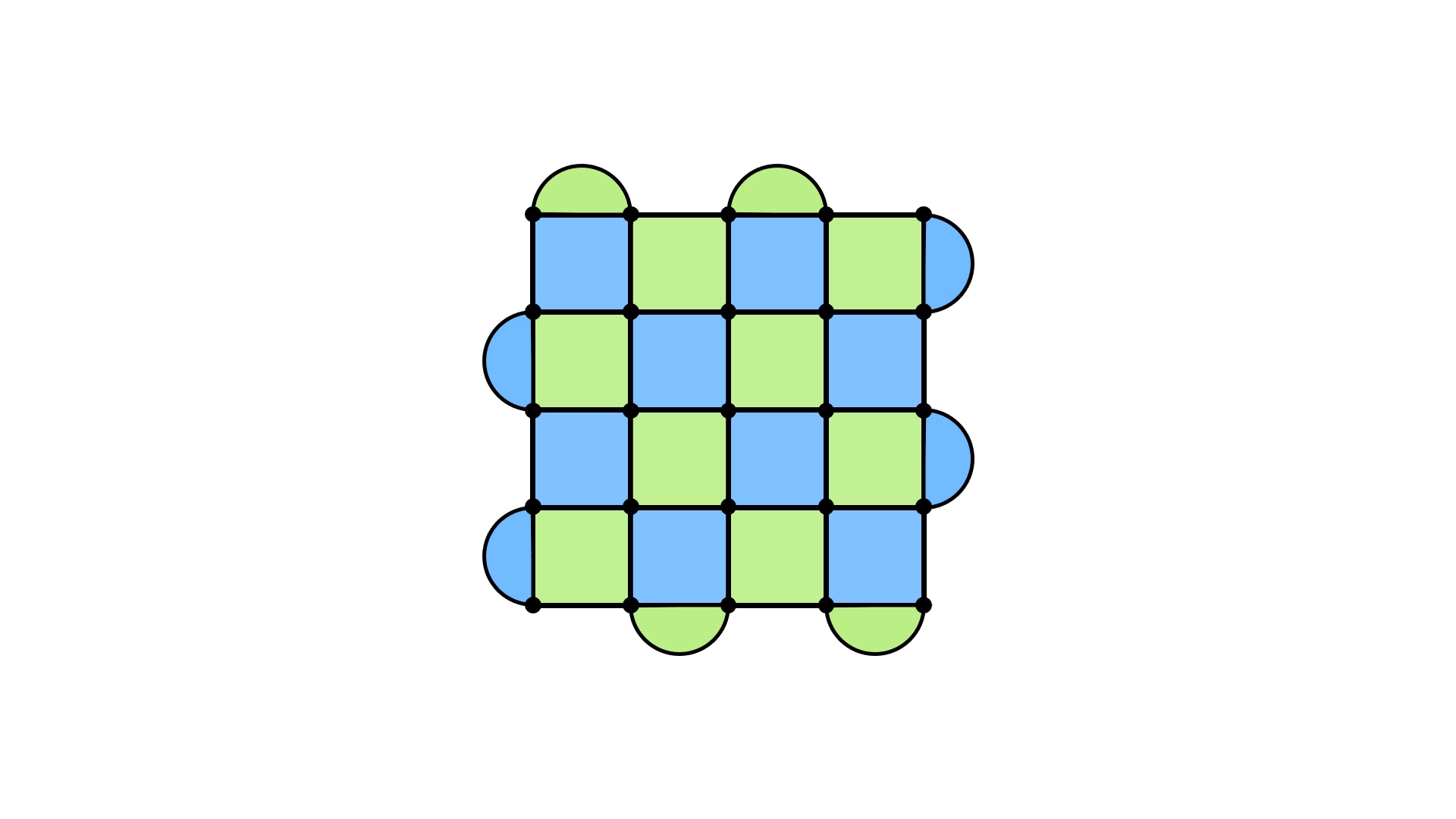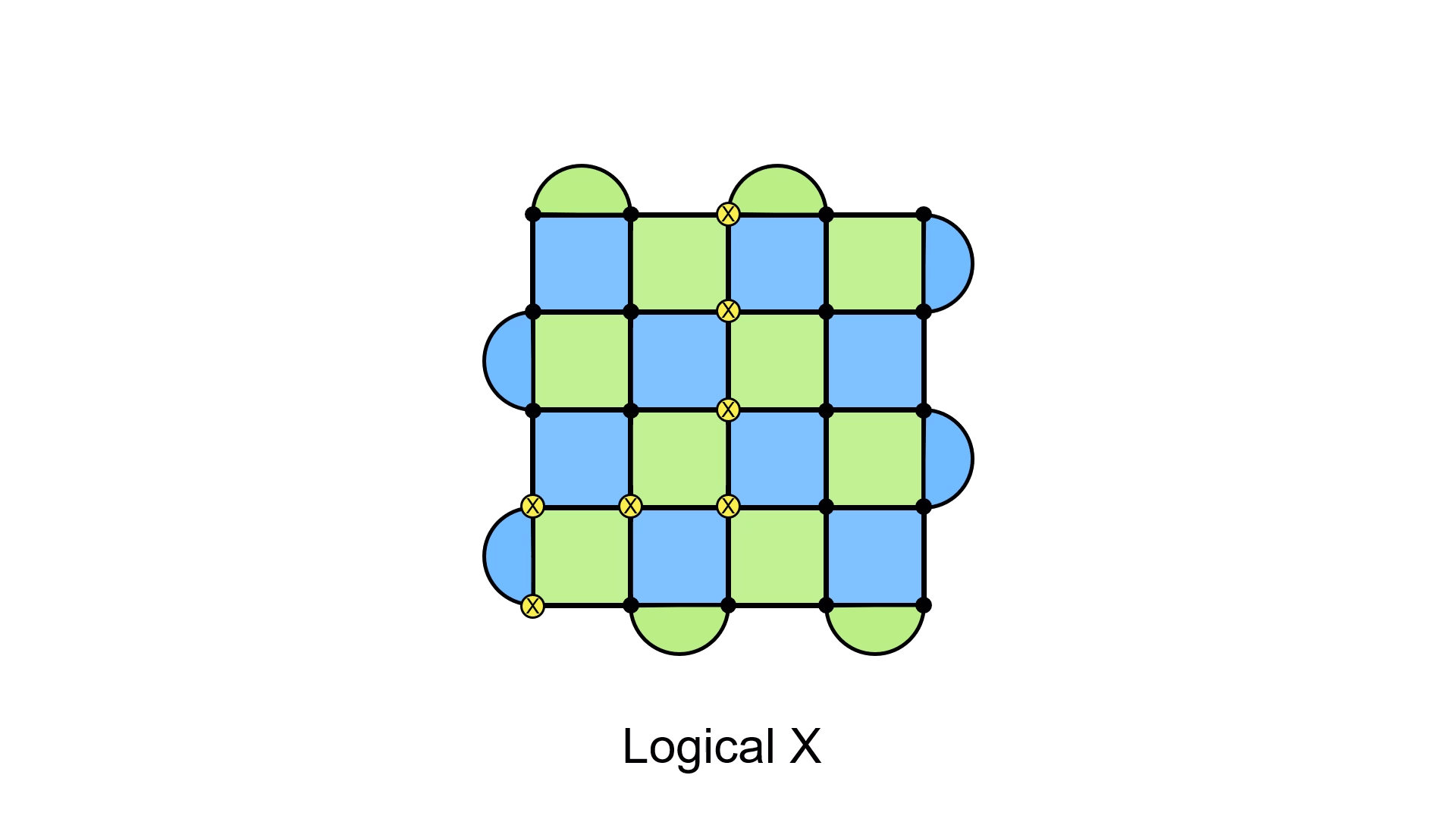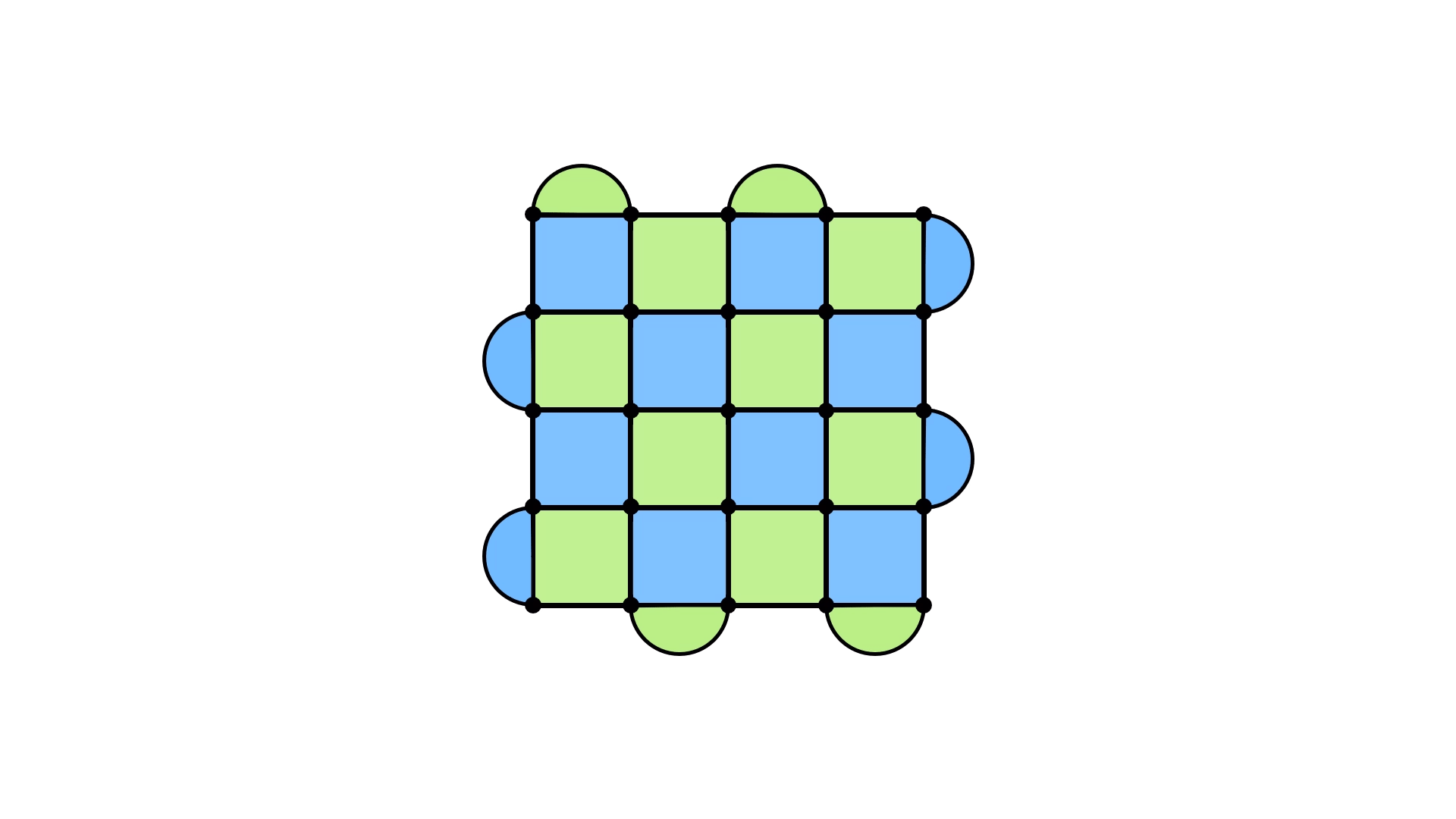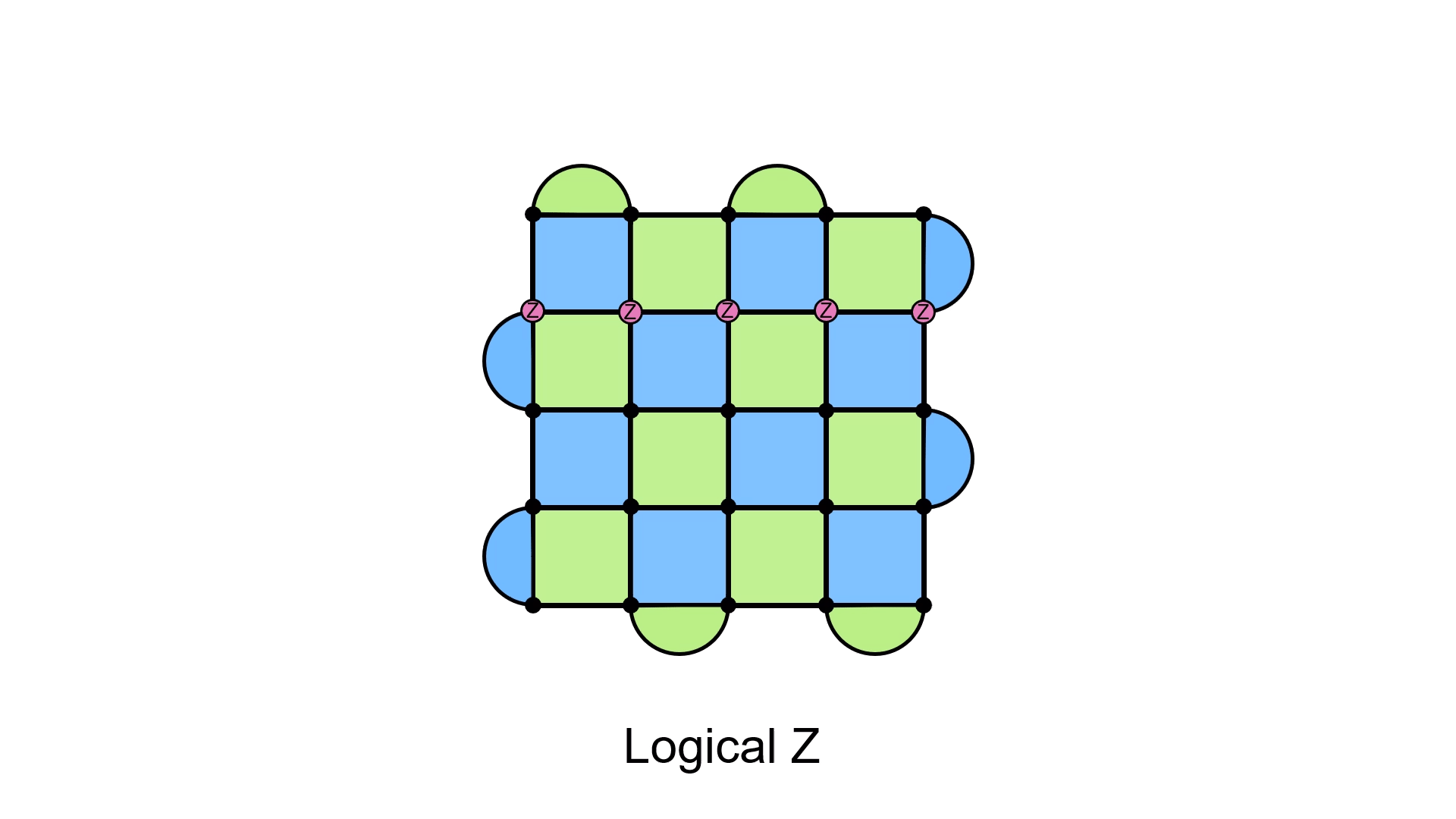
It doesn’t matter if you have the loop going straight along a row, or if you have it zigzagging through the lattice. Almost any loop will do (provided they commute with the stabilizers), and that’s because you can actually “move” these loops by adding stabilizers to the mix. Doing so will just shift the loop, like in the following diagram.
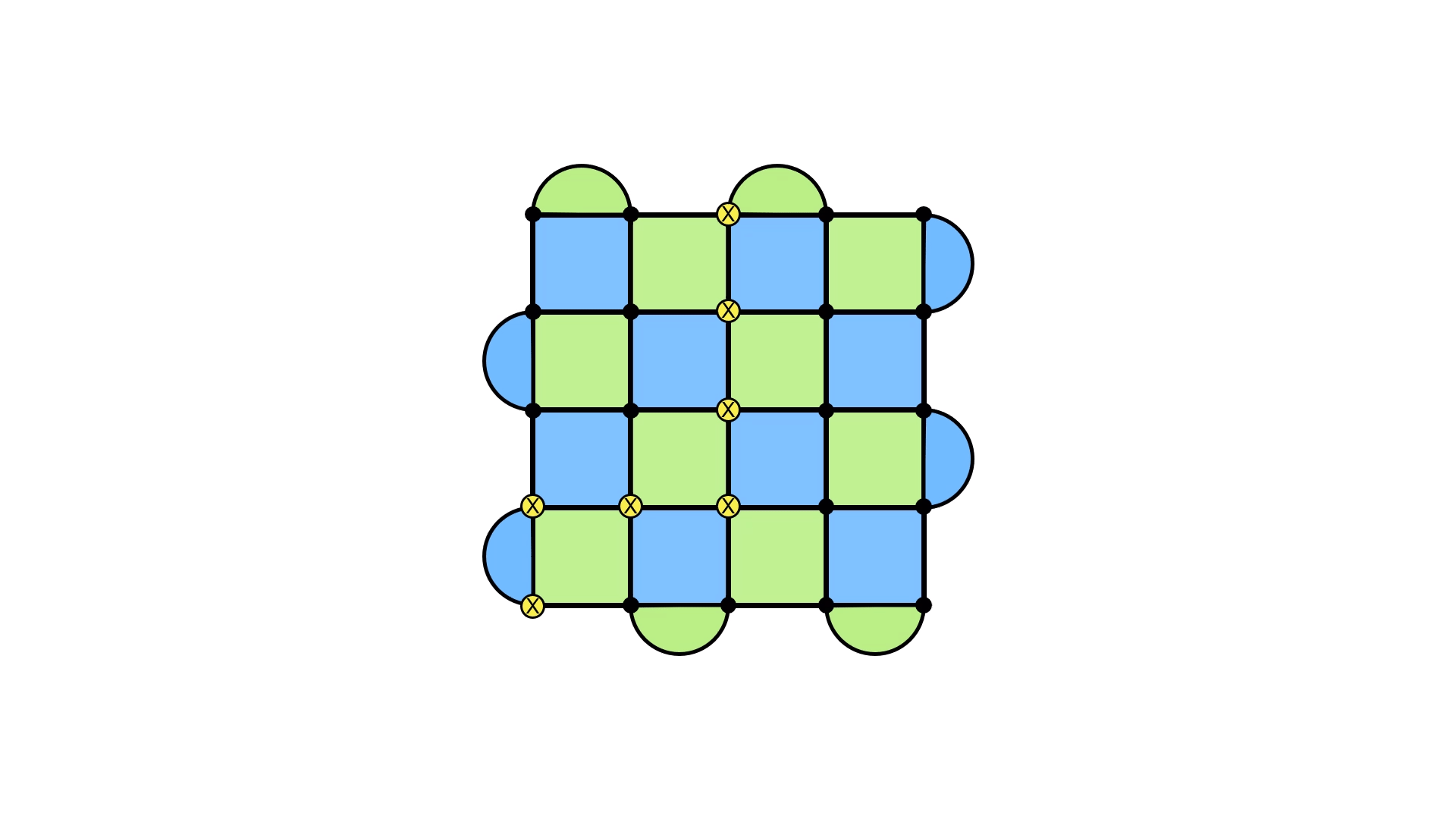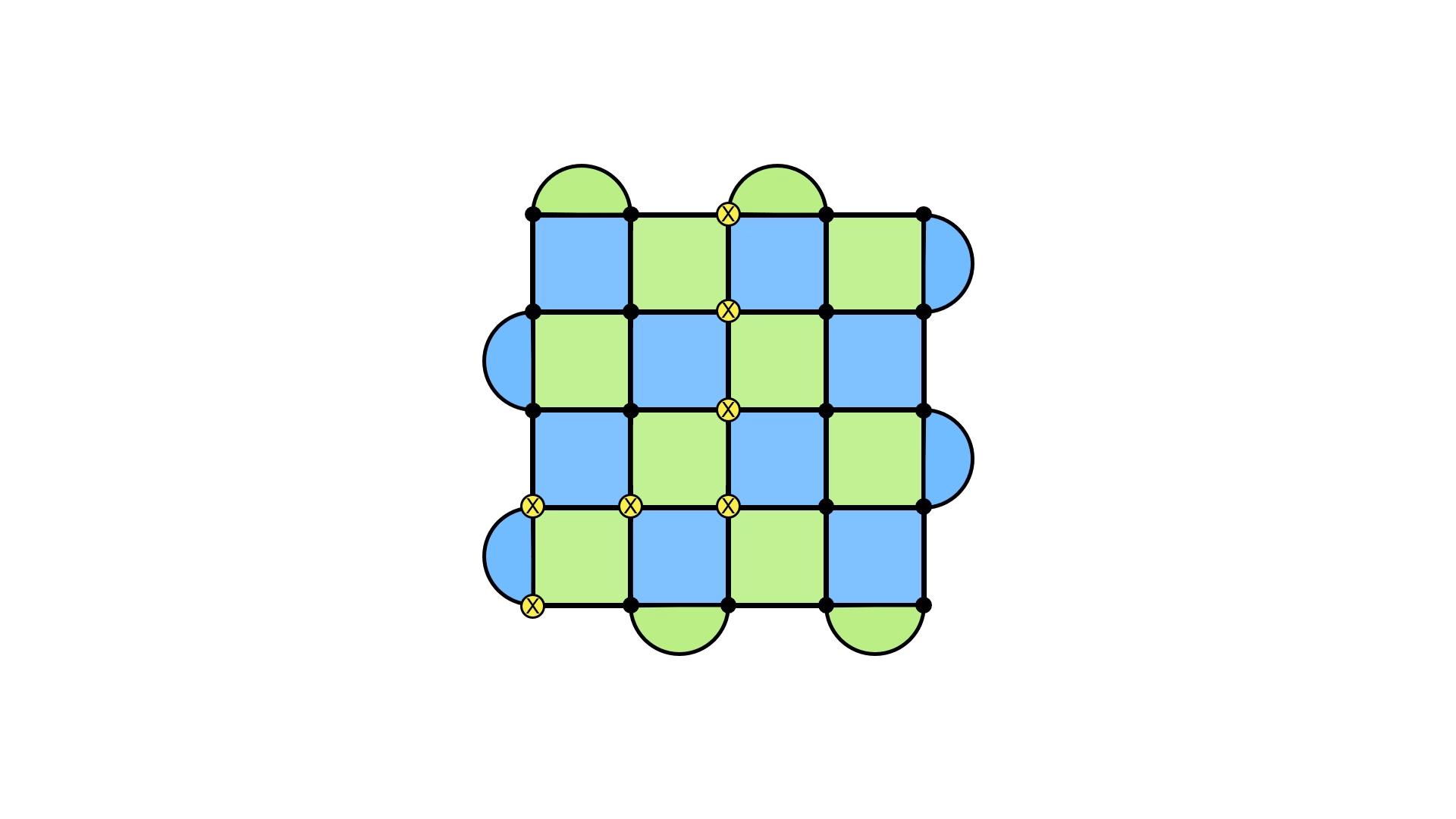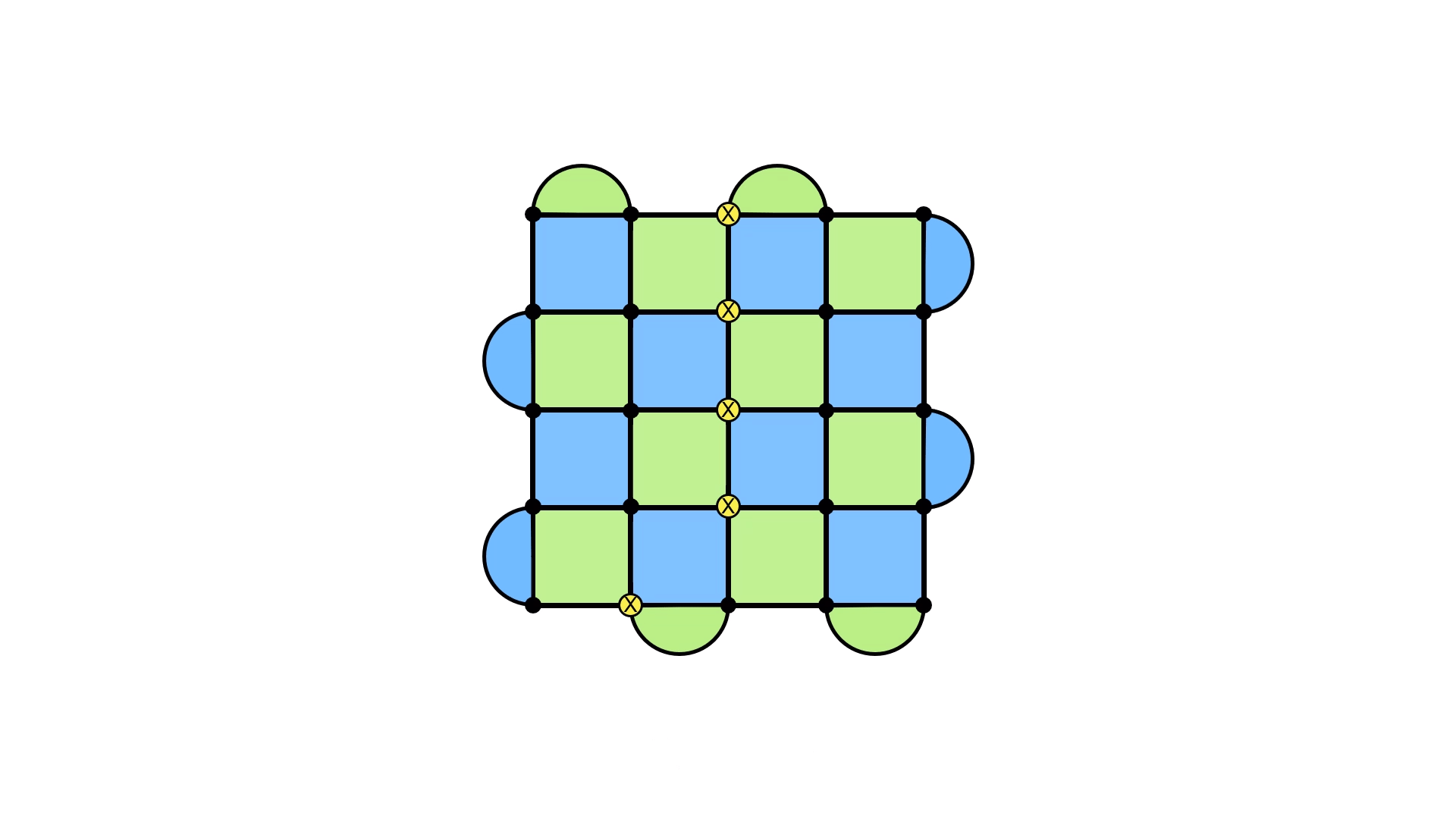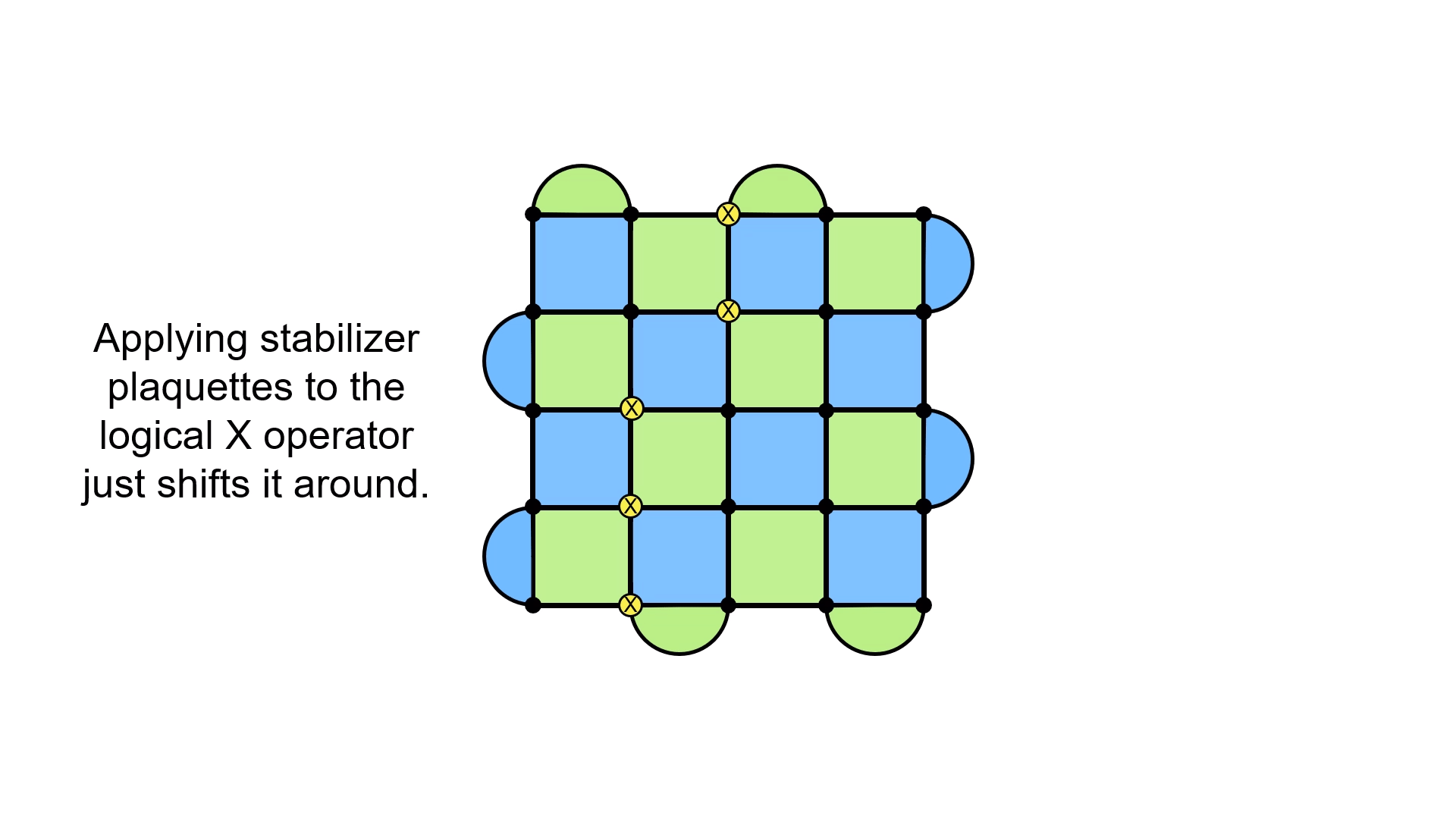
But how do we detect these loops being applied? After all, they don’t show up in our syndrome, which was the tool we were using to detect errors.
The key is that we can implement another operator, which can detect the presence of a loop that goes across the boundary. It turns out that these operators are complementary: to detect if an X loop across the boundaries occurred, we use a Z loop, and vice versa.
Why does this work?
Let’s recall the two kinds of loops we can have (again, I’ll focus on X errors). They can either form loops within the lattice, or they can stretch across the boundaries (the rubber band on a deck of cards image). How does a horizontal Z loop detect the difference?
Again, parity comes to the rescue. Suppose we have a loop of X errors that looks like this.
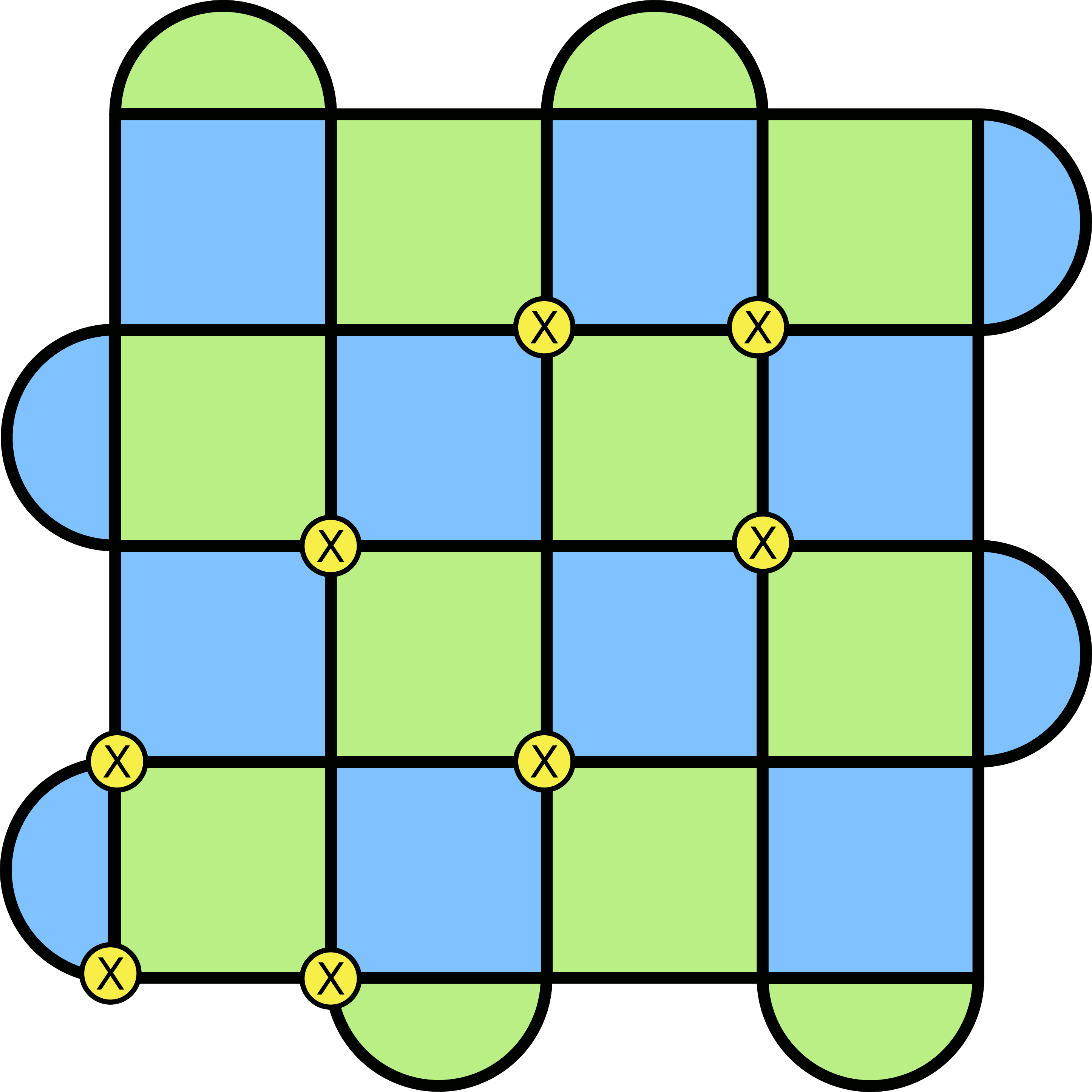
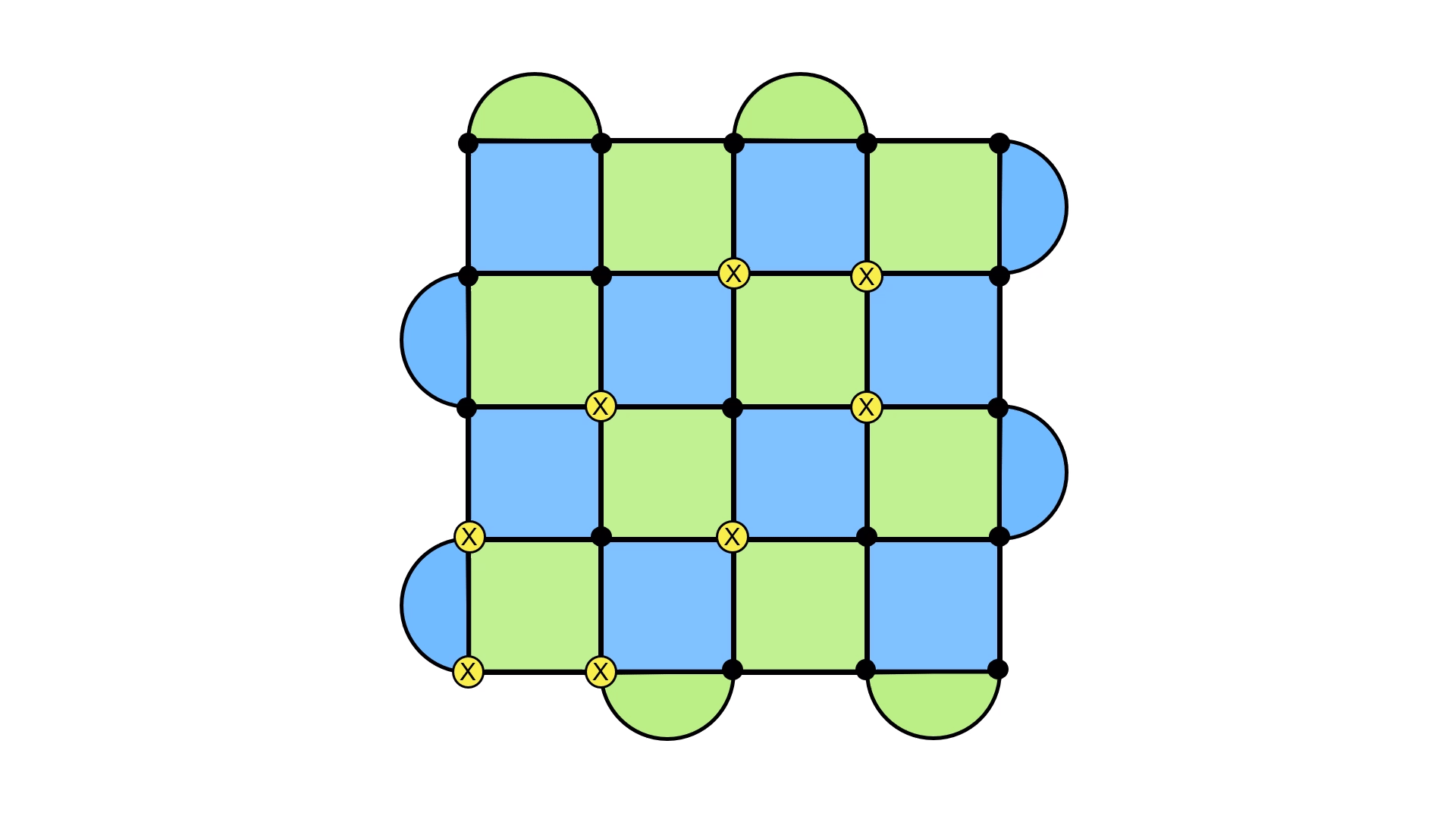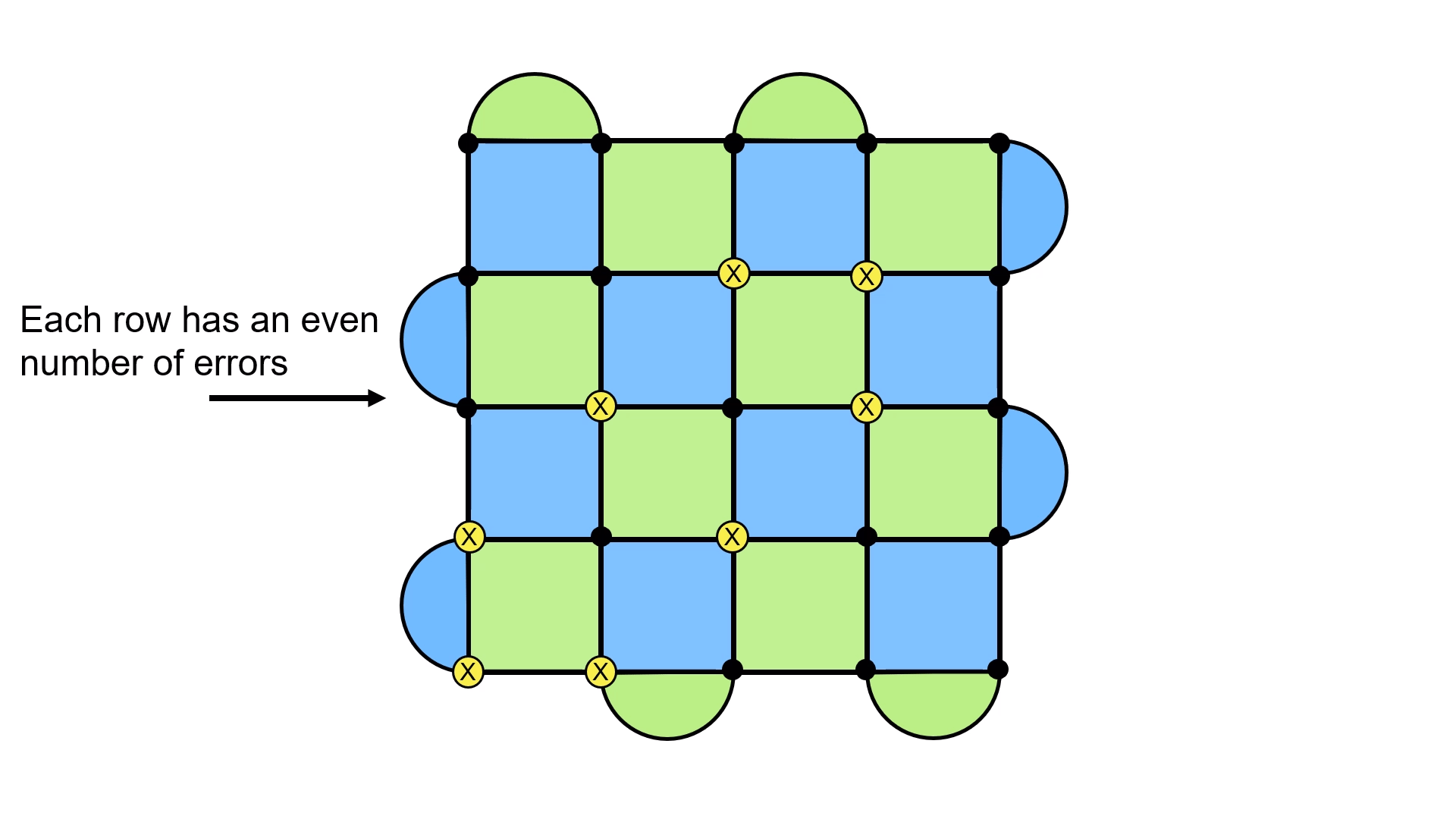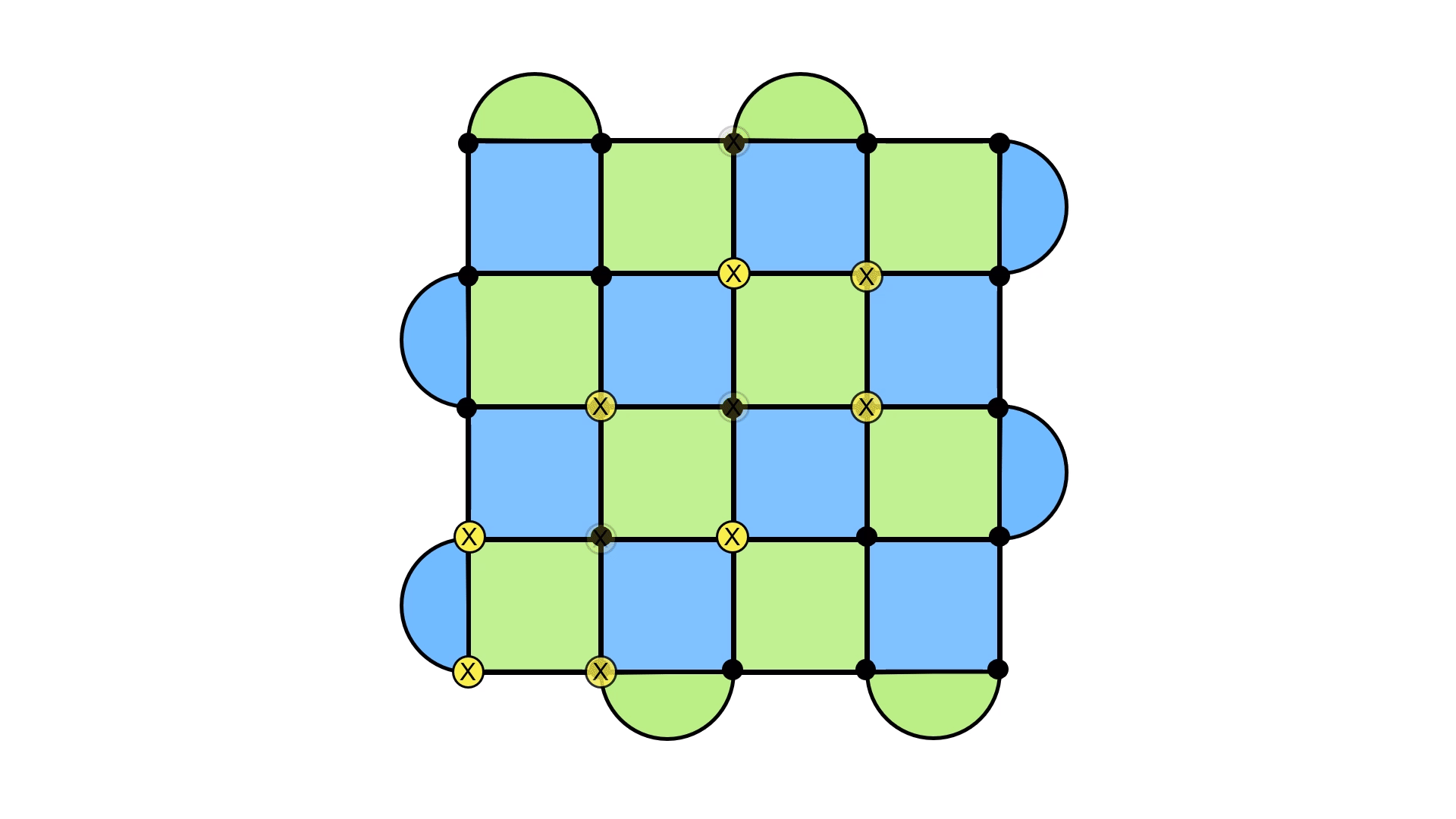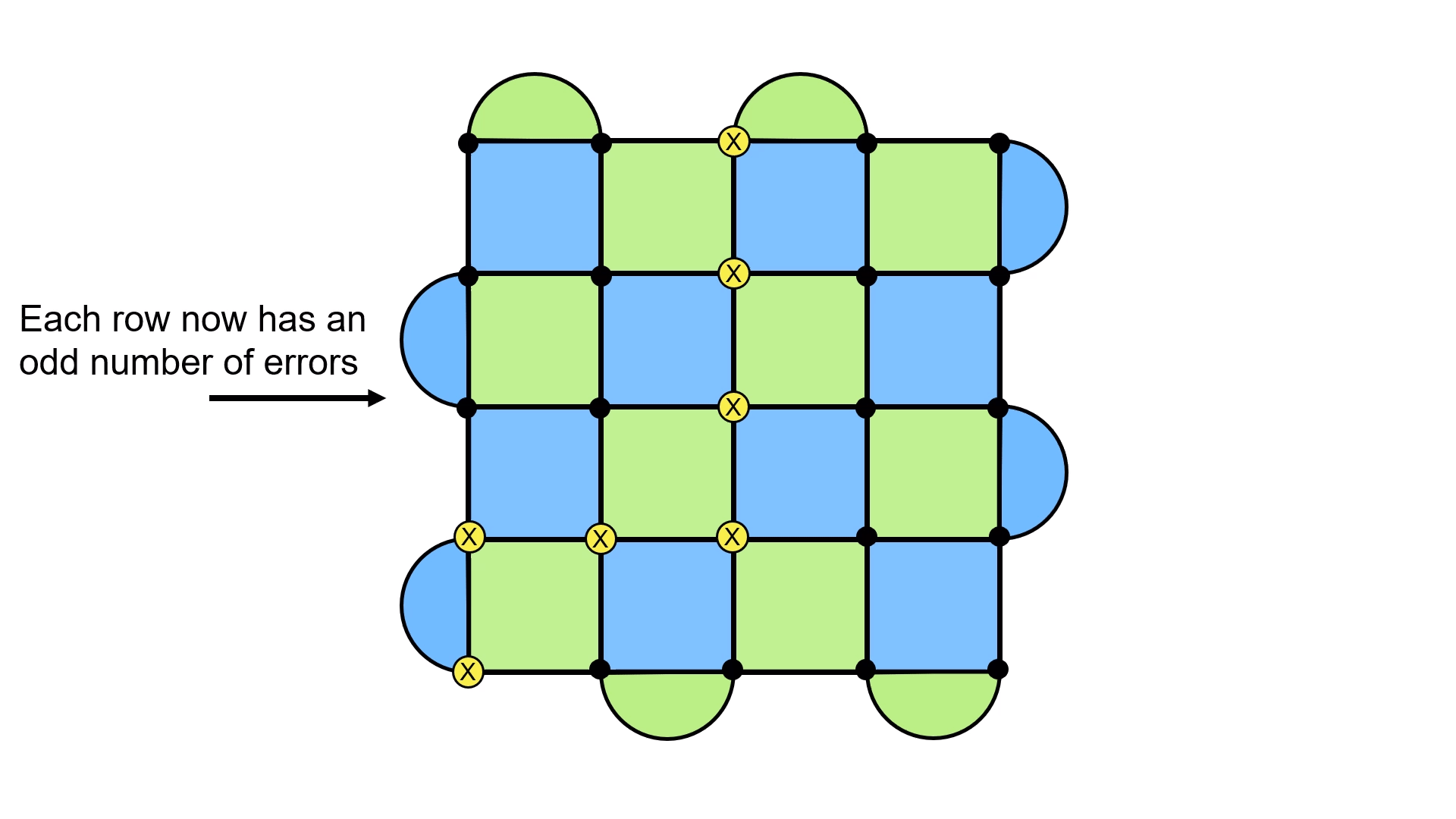
The insight is to look at the rows of the lattice. Do you notice anything in particular about how many X errors there are? It’s an even number! This turns out to be a general feature of these kinds of loops7. The only way to get an odd number is to have the loop stretch across the lattice. This provides a nice way to cleanly distinguish between the two loops.
One thing to keep in mind is that this is all assuming that we know the error + recovery configuration that was applied. We won’t actually know that while running the surface code on hardware. The reason I’m telling you about this then is because these techniques are used to build good software implementations for correcting errors (we’ll get to that shortly).
If we are just working things out with pencil and paper, we don’t need to say anything about using Z loops to detect X loops. Instead, we can just look at the X errors and count along the rows of the lattice. Just keep in mind that what we need to actually do is measure a Z loop in the horizontal direction, which will give us a product of eigenvalues that will be ±1, telling us which “sector” we are in with respect to the Z loop. The same story is true for using X loops to detect Z loops. They are intertwined. This means that the quantum information encoded in our entire lattice can be thought of as living in the two dimensional space carved out by the two loop operators.
These loop operators are what we call logical operators for the surface code. They manipulate the quantum information that is hidden within the entire lattice, not the states of the individual physical qubits. We call them logical X and logical Z because, like the usual Pauli operators, they have the same sort of algebra (they anticommute).
It turns out that the quantum information that is distributed across the whole lattice describes a qubit, which we call the logical qubit. A general feature of surface codes is that they have N2 physical qubits, and only one logical qubit.
Here’s how it works. The lattice has N2 physical qubits, and each one has two degrees of freedom (you can think of them as being spin-1/2 particles). This gives us a total of 2N2 degrees of freedom. But then we have the stabilizers. How many are there? Well, if you look at the lattice, you can break the number of plaquettes up into bulk and boundary plaquettes. Let’s start with the bulk. If the lattice has length N, then there will be N–1 plaquettes on each side (the bulk ones). This means that there are (N–1)2 bulk plaquettes in total.
Next, notice that each boundary has exactly 1/2 the number of half-moon plaquettes compared to the bulk plaquettes making up the row beside them. This means we have (N–1)/2 plaquettes per side, for a total of 4×(N–1)/2 = 2(N–1) half-moon plaquettes.
In total, we then have (N–1)2 + 2(N–1) = N2 – 1 plaquettes. Each one imposes a constraint on the system, since they must have values of ±1. This means two degrees of freedom are lost with each stabilizer plaquette. Putting this all together, the actual degrees of freedom of the surface code are:
Degrees of freedom = 2N2 – 2(N2 – 1) = 2.
In animated form:
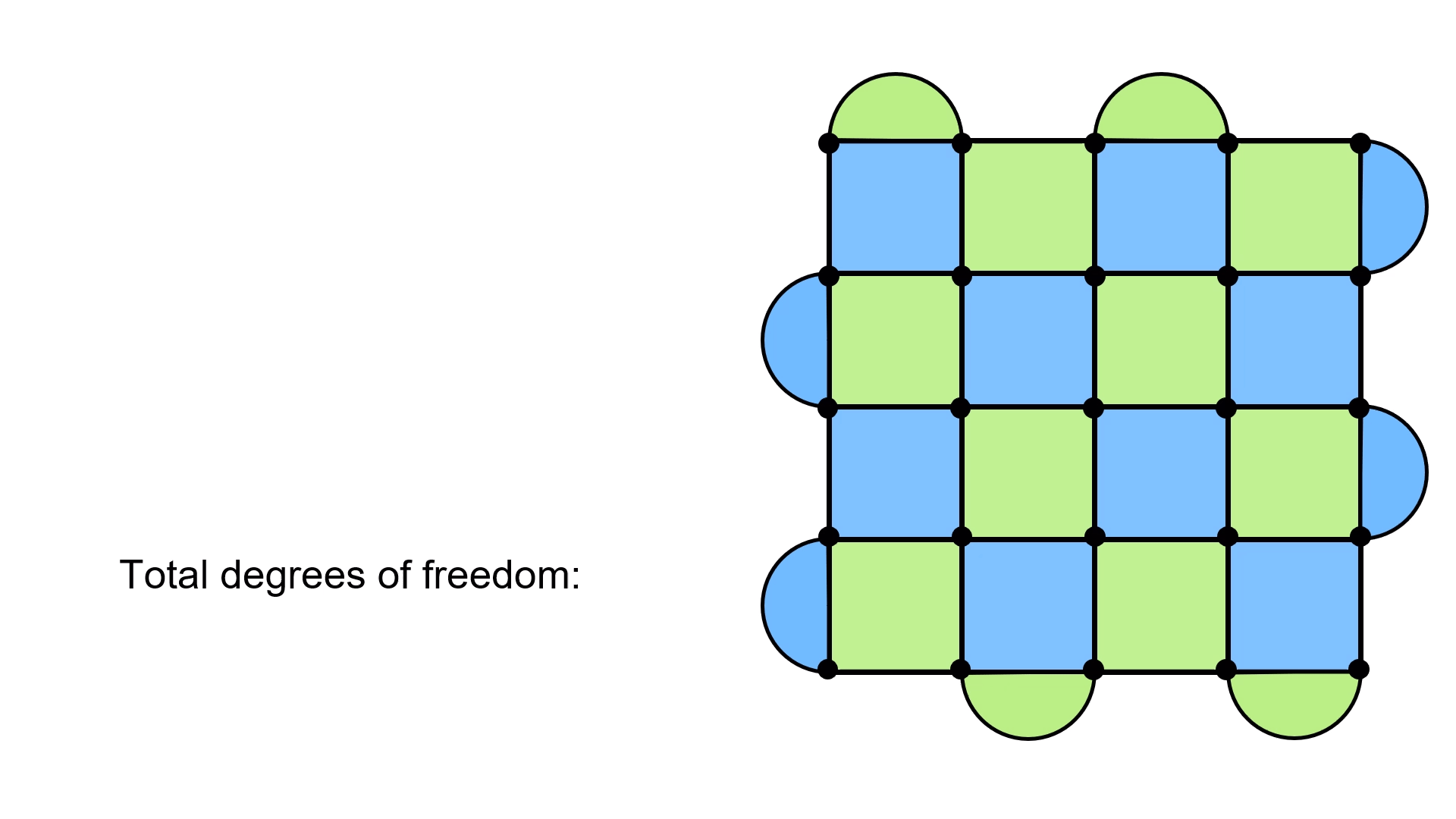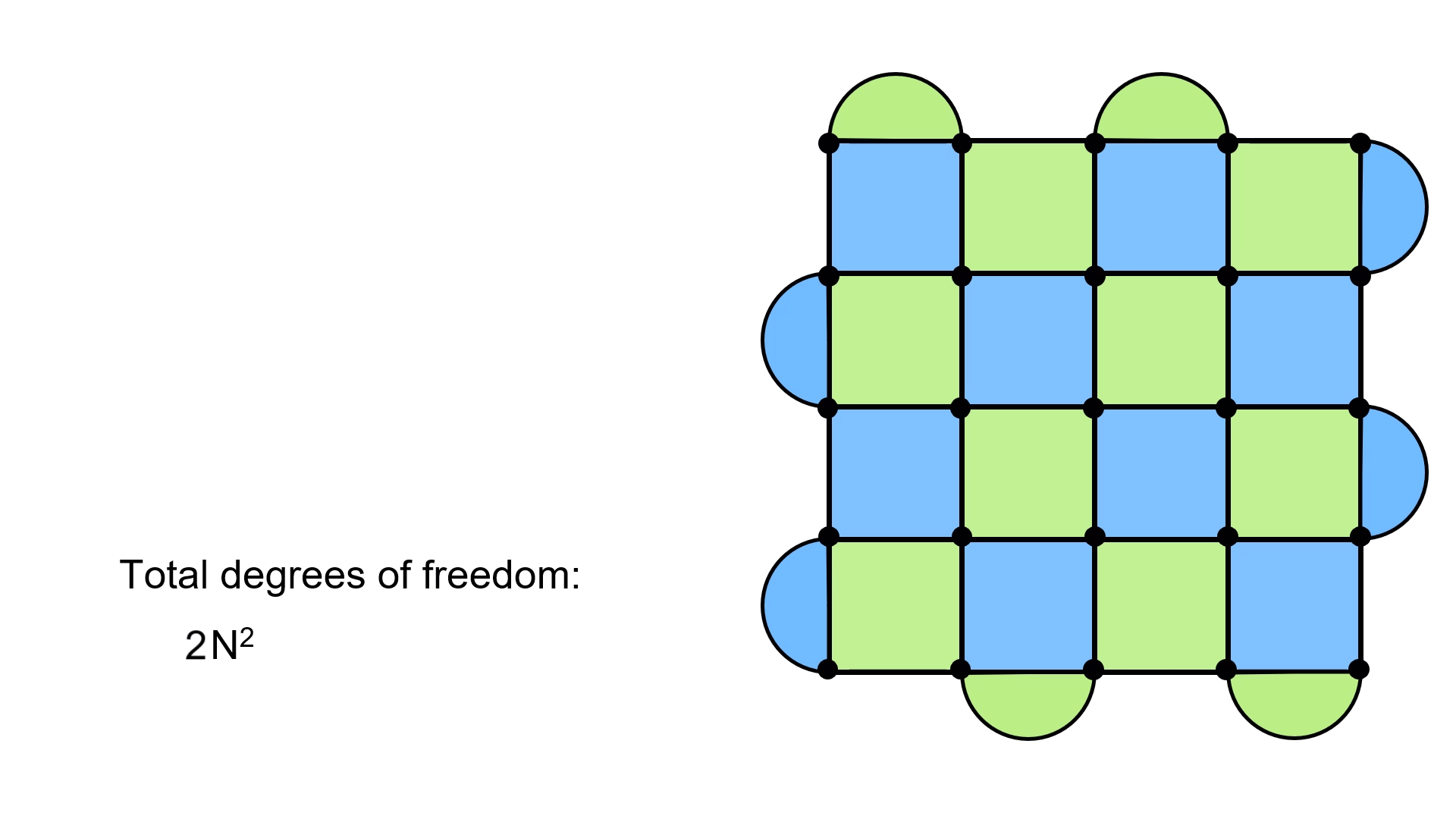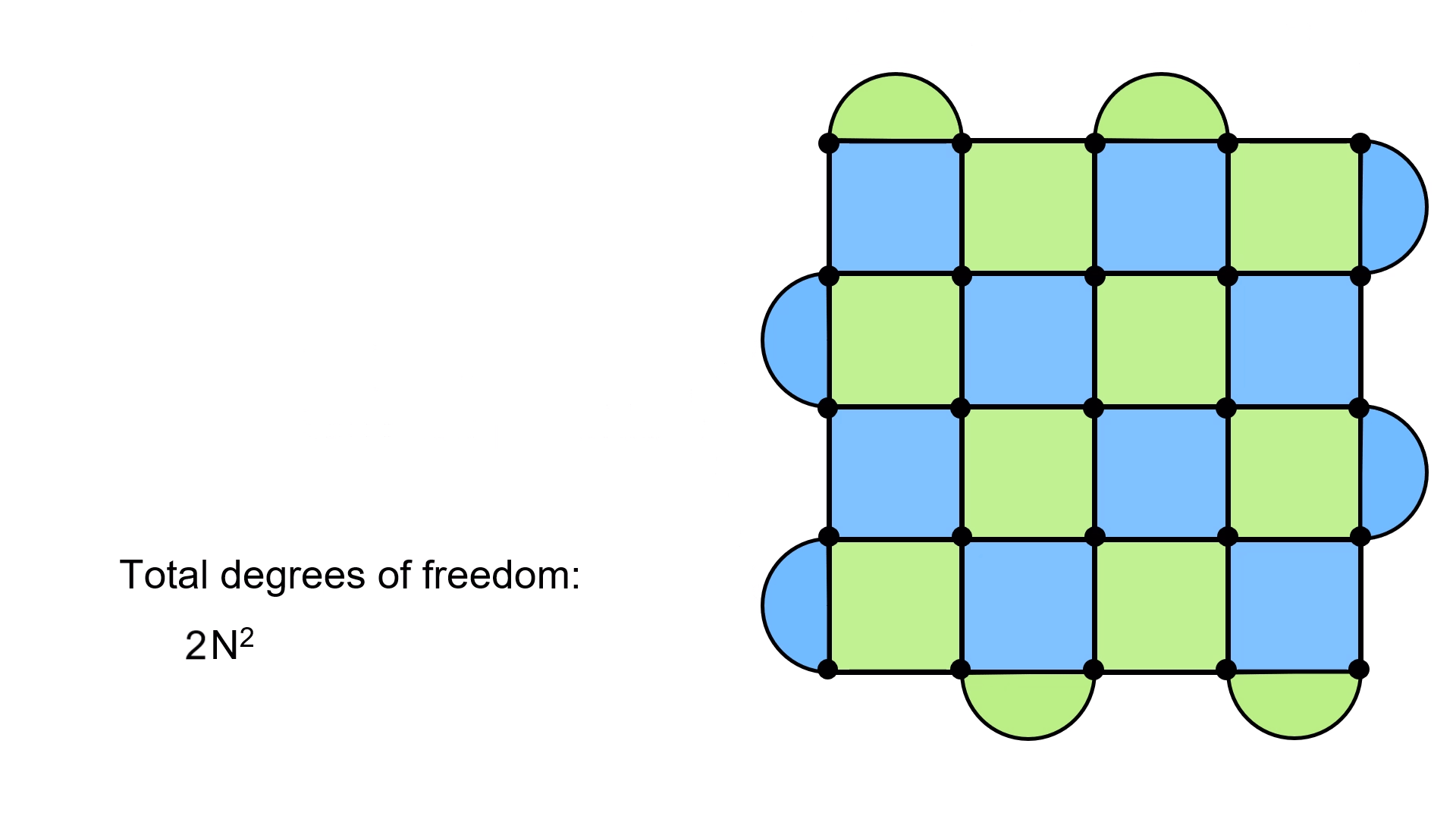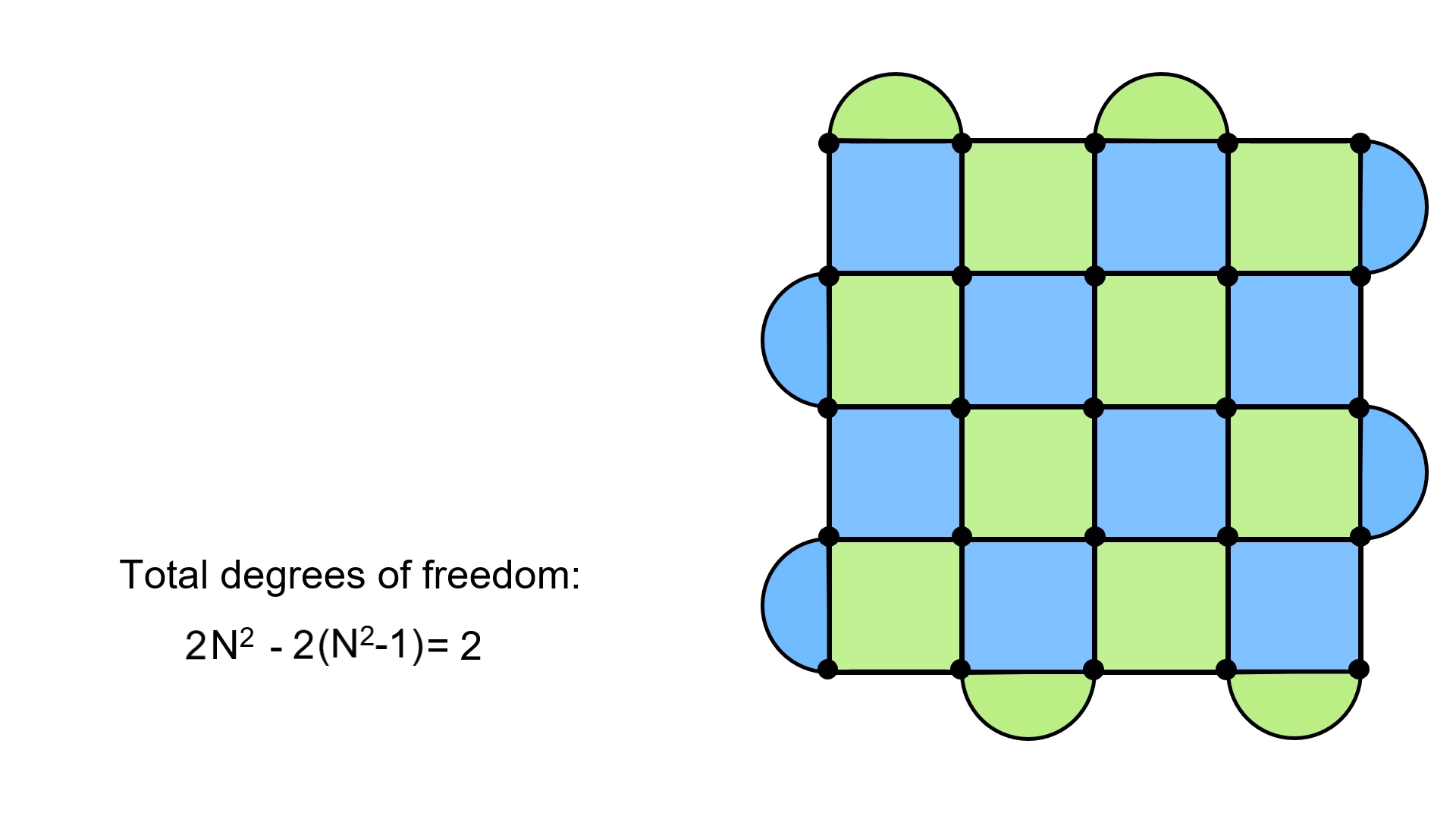
This is exactly the degrees of freedom for a qubit! What this means is that we’ve managed to encode a qubit’s worth of information from N2 physical qubits. We call this one the logical qubit, because it’s the one which is actually used to carry out a quantum computation. This whole technique of detecting errors using stabilizer measurements is for the purpose of protecting this qubit.
And how do we access this logical qubit? After all, it’s not a physical object on the lattice. Instead, it’s sort of “smeared out” across the whole lattice. This is why people sometimes call these kinds of codes “topological”. It reflects the fact that the logical qubit we’re manipulating isn’t located at a specific place on the lattice. The operators used for manipulating this logical qubit are the logical X and Z operators we looked at above, which is why it’s good that we had something which didn’t get detected by the stabilizers.
After a moment’s thought, you might be confused as to why the surface code gets any attention. After all, being only able to create one logical qubit8 out of that many physical qubits looks like a waste. And it only gets trickier as you increase N, with no corresponding increase in the number of logical qubits. So why is the surface code popular?
The answer lies in fault-tolerance. This is a research topic within quantum error correction that concerns itself with making sure that a quantum computing can do all of its computation correctly. In what I described above, we assumed a bunch of things about the errors. Namely, we assumed that errors occur on the lattice during the computation, but not when implementing the syndrome measurement or with applying the corrections. But these are physical processes just like any other! There’s no reason that they should be magically immune to errors, except for the fact that theorists such as myself like simplicity. Unfortunately, the world is far from how a theoretical physicist imagines it, so being able to deal with errors during all steps of a computation is crucial. Answering questions like, “What happens if the syndrome is measured incorrectly?” or “What if a correction that is applied happens with an error?” is the focus of studying fault-tolerance. This is going to get us way off-field from the discussion I want to have in this essay, but it’s worth pointing out that these ideas are the next steps that need to be taken if you ever want to go from this nice theoretical idea to a real implementation in the laboratory.
Main ingredients
This essay has been focused on building up the necessary ideas required to understand the surface code and how it actually works. There are several ingredients involved, so it’s worth recapping what we’ve seen.
The surface code is built up from a square lattice of N2 physical qubits, and they encode one logical qubit. The checkerboard pattern on the surface code is from two kinds of stabilizers, which are plaquettes that can measure the parity of errors (bit flips for X errors and phase flips for Z errors) on the surface code. This gives us an indirect way of detecting errors by constructing its syndrome. In an actual quantum computer that uses the surface code, only the syndrome is seen, not the underlying error configuration.
Correcting the errors ultimately involves constructing loops. These loops are formed from the error + recovery configuration put together, but since we cannot see the error configuration, this can lead to good loops (within the bulk of the surface code) or bad loops (stretching across the surface code’s boundaries). A bad loop can be good if you implement it on purpose (because this lets us manipulate our logical qubit), but it’s bad if you apply it by mistake (logical failure). Being able to form good loops reliably is what leads us to the idea of decoding.
Decoding
We’ve seen that it isn’t easy to do error correction with the surface code. Despite the fact that we have syndromes, they aren’t one-to-one with the possible errors. This wouldn’t be a disaster if only errors were possible on our state, but when the wrong corrections are applied, this can lead to a state with no syndrome yet fundamentally different characteristics. This is what happens when a logical operator is mistakenly applied. And because we don’t have access to the underlying configuration, there’s no way of knowing if we manipulated the quantum state into what we call logical failure.
Here’s what the ideal scenario would look when doing quantum error correction with the surface code.
- We use the helper qubits to measure all of the stabilizers, giving us the syndrome.
- Software takes in the syndrome and outputs a recovery configuration to apply to the lattice.
- The errors are eliminated, the surface code has underwent recovery, and the computation continues.
Ignoring the fact that errors can show up while measuring the syndrome and applying a recovery configuration9, Step 2 is very tricky. Like I just mentioned, the relationship between syndromes and errors isn’t one-to-one, so there’s always a chance that a proposed recovery configuration leads to logical failure (implementing a logical operator by mistake). A good decoder will then minimize this outcome when looking at a given syndrome.
One thing to keep in mind is that this will depend on the physical error rate, which is the probability that a given lattice site will produce an error during the computation. A discussion of error rates will get us way further into the weeds than we’ve already gotten, so I will be brief on this topic. There are many error models, ranging from the simplistic but unrealistic (error rates are independent) to complicated (including correlations between lattice sites and their errors, as well as time-dependence).
One key plot that is shown in work on the surface code is that of the error threshold. As far as I know, this is done for the case in which errors are independent. With your software implementation, you can calculate the logical failure rate Pfail as a function of the physical error rate perror. For a given lattice of side length N, you get a different curve. Then, there’s a threshold physical error rate at which each of these curves cross. The error rate corresponds to pthreshold ≈ 0.109. Such a plot might look like this.
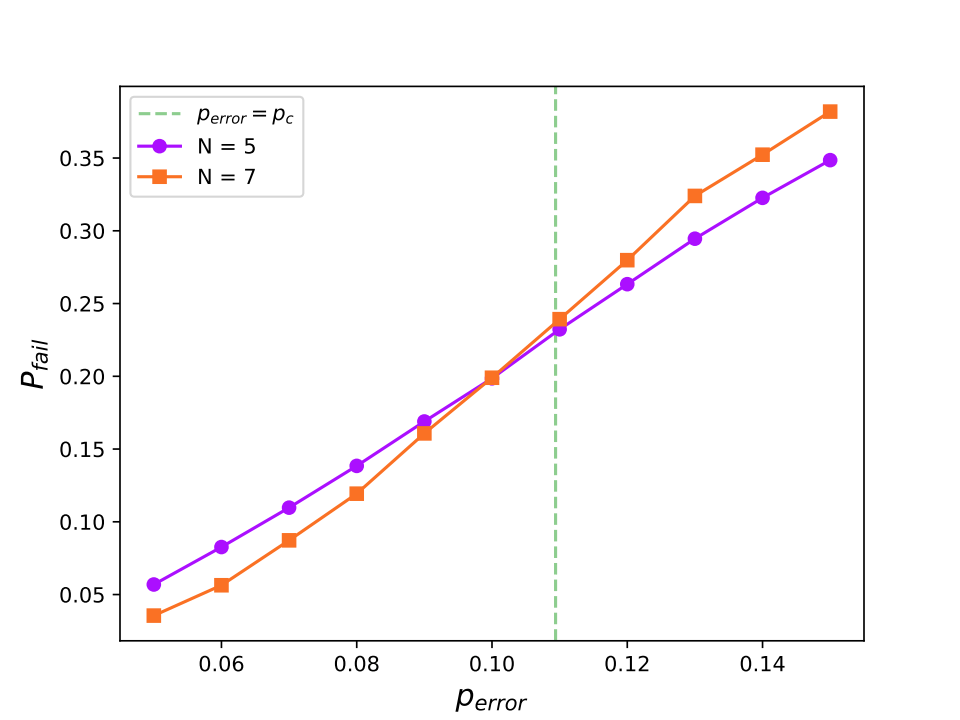
What does the threshold represent? It’s the critical point at which, when you take the lattice size to infinity (otherwise known as the thermodynamic limit), errors can be corrected10. It should be a step function centered at this point. For physical rates below the threshold, recovery can be reliably done, and above it, recovery is impossible. By plotting the Pfail vs perror curves for various values of N, the hope is that they will all cross at this threshold rate and resemble a step function (getting closer and closer to one as N increases).
But how can we construct this plot if we don’t know the underlying error configuration? The idea is that the software implementation gets evaluated on a test set of syndromes and errors. This means we know the underlying error configuration while building the model. The hope is that if we can build a model which recovers the state in an accurate way (independent of the test set), it will work well in various scenarios.
A bunch of work has been done to see which decoder is best11. Proposals include neural network implementations, the standard “Minimum Weight Perfect Matching” algorithm, and many more. Some are more sophisticated than others, but they all play the same game: take in a syndrome, and propose a recovery configuration to apply, while minimizing the logical error rate.
For my essay project as part of Perimeter Scholars International, I worked on building such a good decoder (the plot you see above is from this project). It uses machine learning, and although I am biased, I have to say that it has some pretty neat ideas baked into it. I’ll tell you about it in a future essay.
References
-
Surface codes: Towards practical large-scale quantum computation. A. G. Fowler, M. Mariantoni, J. M. Martinis, A. N. Cleland, arXiv:1208.0928 [quant-ph], 2012.
I would say that this reference has almost everything you need to know about the surface code. The lattice they use is slightly different than mine though, which is why the diagrams don’t perfectly match. I’m pretty sure that the surface code I’ve drawn is called the “rotated” surface code because it takes the one from their article and rotates it by 45 degrees. Still, a lot of the mathematics is worked out here, and it makes for a great place to find a lot of technical details.
-
Reinforcement Learning Decoders for Fault-Tolerant Quantum Computation. R. Sweke, M.S. Kesselring, E.P.L. van Nieuwenburg, J. Eisert, arXiv:1810.07207 [quant-ph], 2018.
This is the reference that I first saw with the kind of diagrams that I used. I loved the design, and that’s why I’ve used this kind of surface code ever since.
-
Topological quantum memory. E. Dennis, A. Kitaev, A. Landahl, J. Preskill, arXiv:quant-ph/0110143, 2002.
The beginning of all this surface code business (as far as I’m aware). I’m putting it in the references for historical purposes. It does have some interesting parts, but I’m not a fan of the presentation. I think a lot of the diagrams are difficult to follow, and the construction they use for the surface code is different than what I used here. My biased opinion is that this graphical approach is much easier to understand, but perhaps you want some more mathematical meat to your surface code. If so, you can go here.
-
A game of surface codes: Large-scale quantum computing with lattice surgery. D. Litinski, Quantum, 3, 128, 2019. arXiv:1808.02892
This is the paper that inspired the name of my project and this essay, which in turn is from A Game of Thrones.
Endnotes
-
Technically, a state is something called a ray in the Hilbert space of the system. This is a fancy way of saying that we actually have a whole group of states that are effectively the “same”, even if they don’t look the same. They are related by something called an overall phase factor, which doesn’t change the underlying quantum state since the main thing we care about is having it be normalized to 1. ↩
-
This comes from the fact that the Pauli matrices aren’t independent. If you actually perform the multiplication, you will find that XZ = −iY, where i is the imaginary unit. This means two things. First, we don’t need to have Y stabilizers since X and Z “cover” the space. And second, when we consider errors, we just have to look at X and Z because both happening on the same site introduces a Y error. In particular, a Y error on the lattice would generate a red dot (syndrome) on all of plaquettes it touches. ↩
-
A Hamiltonian is what physicists use to describe the dynamics of their system. In the game of quantum theory, the Hamiltonian is the object that goes into the Schrödinger equation iℏ ∂t❘ψ(t)❭ = H❘ψ(t)❭. In the case of the surface code, the Hamiltonian is defined in terms of the stabilizers: H = −J ∑p ( Zp + Xp ), with J > 0. This enforces the stabilizers to all have +1 as their eigenvalues, which will yield the lowest energy to the system. ↩
-
Helper or “ancilla” qubits are qubits which don’t form the main part of the algorithm, but serve some purpose. For our case, the helper qubits serve as measuring devices for our stabilizers. This means that each stabilizer has a helper qubit associated with it, apart from the N2 physical qubits we are already using. These are not used for anything else than building the syndrome. ↩
-
Syndromes are a feature of all stabilizer codes, with some codes doing better than others in mapping one specific error to a certain syndrome. If you have a code that can do this, then you can correct errors, since you just have to make a “translator” that tells you that this syndrome corresponds to this error, and act accordingly. ↩
-
These are called homology classes, and for our purposes, they roughly classify what kind of loop we have. There’s a lot more to unpack here mathematically, but I won’t get into it. ↩
-
The reason each loop has an even number of X errors when looking at them by row has to do with the fact that they are built from stabilizers, and any loop has to “wrap back” on itself. This means you have to cross a row an even number of times before returning to your starting point. This won’t be obvious at first, but once you play around with a few examples, you will see the principle at work. ↩
-
For the surface code, we were able to create a logical X and Z operator by taking advantage of how each boundary only has one plaquette colour. This means we only get one logical X and one logical Z operator. However, if we used the surface code’s close cousin, the toric code, we can upgrade the number of logical qubits we have from one to two. The reason is that the periodic boundary conditions of the toric code allow you to define a logical X operator along both the horizontal and vertical directions (the same is true for Z). Analyzing the degrees of freedom leads to the result that you get four degrees of freedom, or two logical qubits. ↩
-
This is called fault-tolerance. The idea is that errors will accumulate during all steps of a computation, and being able to stand robust against all of them is critical to getting any computation to work. ↩
-
The threshold rate was found by establishing a mapping between the surface code and a random-bond Ising model, which has a critical point at this threshold. The details aren’t important for this essay, but if you want to know more, Reference 3 has some discussion about it in Section IV, part F. ↩
-
How do we define “best”? There are two aspects at play. On the one hand, we want a decoder which makes the fewest mistakes possible, which means we want to minimize Pfail. On the other hand, I don’t care how good your decoder is if it’s too slow. After all, we’re hoping to implement these during a computation, so time is of the essence. If you’re slower than the rate at which errors occur, the decoder will become overwhelmed and be of no use. So there’s a tradeoff to be made between accuracy and efficiency. For an actual quantum computer, we need the decoder to be good at both. ↩